
The Role of AI in Real-Time Fraud Detection in Financial Transactions is exploding. Forget dusty old fraud prevention methods – we’re talking AI-powered systems that can sniff out suspicious activity in *real-time*. With financial fraud on the rise and traditional methods struggling to keep up, AI offers a game-changing solution, analyzing massive datasets to identify patterns humans simply miss. This isn’t just about catching bad guys; it’s about safeguarding billions of transactions daily, protecting both businesses and consumers.
This deep dive explores how different AI algorithms, from machine learning to deep learning, are being deployed to detect and prevent fraud. We’ll unpack the importance of data quality, the challenges of imbalanced datasets, and the ethical considerations that come with using AI in finance. Get ready to unravel the complexities and future potential of this crucial technology.
Introduction to Real-Time Fraud Detection in Financial Transactions: The Role Of AI In Real-Time Fraud Detection In Financial Transactions
The digital age has revolutionized financial transactions, offering unprecedented speed and convenience. However, this rapid evolution has also created a fertile ground for sophisticated fraudsters, leading to a dramatic increase in financial crimes. From credit card scams and identity theft to account takeovers and investment fraud, the financial landscape is constantly under siege, resulting in billions of dollars in losses annually and severely impacting consumer trust and the stability of financial institutions.
The impact extends beyond monetary losses. Reputational damage for businesses is significant, impacting customer loyalty and potentially leading to legal repercussions. For individuals, fraud can lead to financial ruin, identity theft, and significant emotional distress. The need for robust and effective fraud detection mechanisms has therefore never been greater.
Traditional fraud detection methods, often relying on rule-based systems and static thresholds, are struggling to keep pace with the evolving tactics of fraudsters. These methods often lag behind real-time transactions, creating a window of opportunity for fraudulent activities to occur before detection. Their reliance on pre-defined rules makes them inflexible and unable to adapt to the dynamic nature of fraud schemes. Furthermore, these systems often generate a high volume of false positives, leading to unnecessary investigations and operational inefficiencies.
AI offers a powerful solution to these limitations. Its ability to analyze vast amounts of data in real-time, identify complex patterns, and learn from past experiences provides a significant advantage over traditional methods. Machine learning algorithms can adapt to new fraud techniques as they emerge, significantly improving the accuracy and effectiveness of fraud detection. AI-powered systems can also automate many aspects of the fraud detection process, reducing the workload on human investigators and freeing them to focus on more complex cases.
AI Techniques Used in Real-Time Fraud Detection
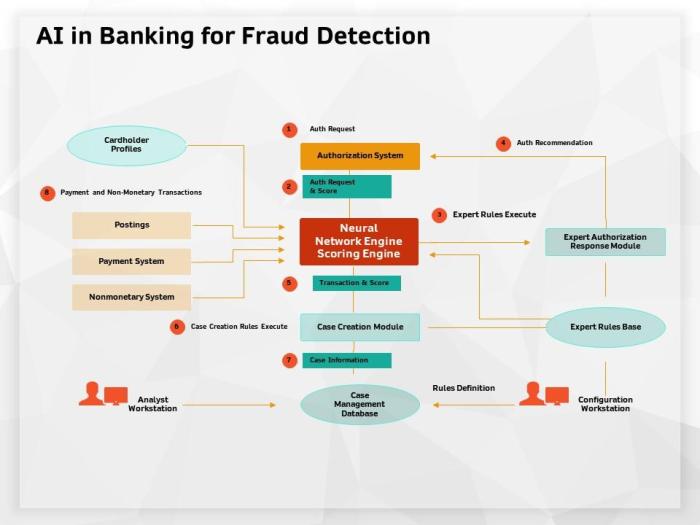
Source: amazonaws.com
AI’s real-time fraud detection in finance is a game-changer, instantly flagging suspicious transactions. This precision is crucial, mirroring the need for secure systems in other areas, like online voting. For example, the integrity of elections could be significantly boosted by the technology discussed in this article: The Role of Blockchain in Creating Secure Online Voting Systems.
Similarly, AI’s rapid analysis helps financial institutions maintain robust security against sophisticated fraud attempts.
Real-time fraud detection in the financial sector is a high-stakes game, and Artificial Intelligence (AI) is rapidly becoming the key player. The sheer volume and velocity of transactions necessitate sophisticated systems capable of identifying anomalies instantly, before fraudulent activities cause significant financial losses. This section explores the core AI techniques driving this revolution.
AI Algorithms in Fraud Detection
Several AI algorithms are instrumental in detecting fraudulent financial transactions in real-time. Their effectiveness varies depending on the specific type of fraud and the characteristics of the available data. The following table provides a comparative overview of three prominent algorithms.
| Algorithm | Description | Advantages | Disadvantages |
|---|---|---|---|
| Machine Learning (ML) | ML algorithms use historical data to build models that identify patterns indicative of fraud. These models learn from past fraudulent and legitimate transactions to classify new transactions accordingly. Common ML techniques include logistic regression, support vector machines (SVMs), and decision trees. | Relatively easy to implement and interpret; can handle large datasets efficiently; adaptable to various fraud types. | Performance depends heavily on the quality and quantity of training data; may struggle with novel fraud patterns; requires regular retraining. |
| Deep Learning (DL) | DL, a subset of ML, employs artificial neural networks with multiple layers to analyze complex data patterns. It excels at identifying subtle relationships and non-linear patterns often missed by simpler ML algorithms. Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) are frequently used in fraud detection. | Can detect complex and evolving fraud patterns; highly accurate in identifying subtle anomalies; requires less feature engineering than traditional ML. | Requires significant computational resources and large datasets for training; can be difficult to interpret and debug; prone to overfitting if not carefully trained. |
| Neural Networks (NNs) | NNs are interconnected nodes (neurons) organized in layers that process information. They learn by adjusting the weights of connections between neurons based on the input data. Different architectures, like feedforward NNs and recurrent NNs, are tailored to specific fraud detection tasks. | Can handle high-dimensional data; capable of learning complex non-linear relationships; adaptable to different data types. | Requires significant training time and data; can be computationally expensive; susceptible to overfitting and bias if not properly trained and validated. |
Algorithm Effectiveness in Different Scenarios
The effectiveness of these algorithms varies depending on the nature of the fraudulent activity. For instance, in credit card fraud, where patterns are often relatively straightforward (e.g., unusual transaction amounts or locations), simpler ML algorithms like logistic regression might suffice. However, for more sophisticated fraud schemes, such as insider trading or money laundering, which involve complex networks and subtle interactions, deep learning models are often more effective due to their ability to uncover hidden relationships within large datasets. For example, a deep learning model might identify a pattern of seemingly innocuous transactions that, when viewed collectively, reveal a larger money laundering operation.
The Role of Big Data and Data Analytics
AI-driven fraud detection systems rely heavily on big data and advanced analytics. The ability to process and analyze massive volumes of transactional data – including transaction amounts, locations, times, customer profiles, and network connections – is crucial for identifying subtle anomalies that might indicate fraudulent activity. Data analytics techniques, such as anomaly detection, clustering, and association rule mining, are used to extract meaningful insights from this data, which then informs the AI models’ training and decision-making processes. For instance, analyzing historical data might reveal that fraudulent transactions often occur during specific times or from particular geographic locations. This information can then be used to improve the accuracy and efficiency of the fraud detection system. Without access to this rich data source and the analytical capabilities to interpret it, the effectiveness of even the most sophisticated AI algorithms would be significantly limited.
Data Preprocessing and Feature Engineering for AI Models
Building robust AI models for real-time fraud detection hinges on the quality of the data fed into them. Garbage in, garbage out, as the saying goes. This section delves into the crucial steps of data preprocessing and feature engineering, ensuring our AI models are equipped to effectively identify fraudulent transactions.
Data preprocessing is the foundation upon which accurate fraud detection is built. Without clean, consistent, and relevant data, even the most sophisticated AI algorithm will struggle to perform effectively. This involves handling missing values, addressing inconsistencies, and transforming data into a format suitable for AI model training. Feature engineering, on the other hand, focuses on creating new features from existing ones to improve model performance. This is where the real magic happens, transforming raw data into insightful signals that can accurately pinpoint fraudulent activity.
Data Quality and Cleaning
The importance of data quality in fraud detection cannot be overstated. Inaccurate, incomplete, or inconsistent data can lead to flawed models that produce false positives (flagging legitimate transactions as fraudulent) or false negatives (missing actual fraudulent transactions). This can result in significant financial losses and damage to customer trust. The data cleaning process typically involves handling missing values (e.g., imputation using mean, median, or more sophisticated techniques), identifying and correcting inconsistencies (e.g., standardizing date formats, currency codes), and removing outliers (e.g., transactions with unusually high values). For example, a missing transaction amount might be imputed using the average transaction amount for that customer, while an inconsistent date format might be standardized to YYYY-MM-DD. Robust data quality checks and validation are critical to ensure the reliability of the resulting AI model.
Feature Engineering for AI Models
Feature engineering is the art of transforming raw data into features that are more informative and predictive for the AI model. This involves selecting relevant features, creating new features from existing ones, and transforming features to improve model performance. For fraud detection, this could involve creating features such as transaction amount relative to the customer’s average transaction amount, transaction frequency, time since last transaction, location-based features (e.g., distance from the customer’s registered address), device information (e.g., IP address, device type), and merchant category code (MCC). For instance, a feature indicating whether a transaction is significantly larger than the customer’s usual spending patterns would be highly indicative of potential fraud. Another example could be a feature representing the velocity of transactions—the number of transactions made within a short period. A sudden spike in transaction velocity could signal fraudulent activity.
Handling Imbalanced Datasets
Fraudulent transactions are typically a small fraction of the total number of transactions. This creates an imbalanced dataset, where the majority class (legitimate transactions) significantly outweighs the minority class (fraudulent transactions). This imbalance can lead to AI models that are biased towards predicting the majority class (legitimate transactions), resulting in a high number of false negatives. Several techniques can be employed to address this issue. One common approach is oversampling the minority class (fraudulent transactions) by duplicating existing examples or generating synthetic samples using techniques like SMOTE (Synthetic Minority Over-sampling Technique). Alternatively, undersampling the majority class can also be used, but this might lead to a loss of valuable information. Another strategy is to adjust the class weights in the AI model’s training process, giving more importance to the minority class. For example, in a model trained with a weighted loss function, a fraudulent transaction might be assigned a much higher weight than a legitimate transaction, thus penalizing misclassifications of fraudulent transactions more heavily. This ensures the model learns to effectively identify the rare but critical fraudulent cases.
Model Training, Evaluation, and Deployment
Training an AI model for real-time fraud detection involves a meticulous process of feeding the model vast amounts of historical transaction data, carefully labeled as fraudulent or legitimate. This data allows the model to learn patterns and anomalies indicative of fraudulent activity. The model then uses this learned knowledge to predict the likelihood of future transactions being fraudulent. The efficiency and accuracy of this prediction directly impact the system’s effectiveness in preventing financial losses.
The training process itself typically involves iterative steps of data feeding, model adjustment, and performance evaluation. This iterative refinement is crucial to optimize the model’s ability to accurately identify fraudulent transactions while minimizing false positives – incorrectly flagging legitimate transactions as fraudulent. Different machine learning algorithms, such as neural networks, support vector machines, or random forests, may be employed, each with its own strengths and weaknesses in handling the complexity of fraud detection data. The choice of algorithm often depends on the specific characteristics of the available data and the desired performance metrics.
Model Training Techniques
The training of a fraud detection model involves several key steps. First, the labeled dataset (transactions marked as fraudulent or legitimate) is split into training, validation, and testing sets. The training set is used to train the model, the validation set is used to tune hyperparameters and prevent overfitting, and the testing set provides an unbiased evaluation of the model’s performance on unseen data. Different algorithms, like gradient boosting machines or deep learning networks, are then applied to learn the patterns from the training data. The model’s parameters are adjusted iteratively to minimize the error rate on the training and validation sets. This process involves techniques like backpropagation (for neural networks) or gradient descent, which adjust the model’s internal parameters to improve its predictive accuracy. The ultimate goal is to create a model that generalizes well to unseen data and accurately predicts fraud in real-time transactions.
Model Evaluation Metrics
Evaluating the performance of a fraud detection model requires careful consideration of several key metrics. These metrics provide insights into the model’s ability to accurately identify fraudulent transactions while minimizing false positives. Crucially, these metrics help determine whether the model is fit for purpose in a real-world setting.
- Precision: Measures the proportion of correctly identified fraudulent transactions out of all transactions flagged as fraudulent. A high precision indicates that the model produces few false positives.
- Recall: Measures the proportion of correctly identified fraudulent transactions out of all actual fraudulent transactions. A high recall indicates that the model successfully identifies most fraudulent transactions.
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure of the model’s overall performance. A high F1-score indicates a good balance between precision and recall.
- AUC-ROC (Area Under the Receiver Operating Characteristic Curve): A comprehensive measure that considers the trade-off between the true positive rate (sensitivity) and the false positive rate (1-specificity) across various thresholds. A higher AUC-ROC value indicates better model performance.
For example, a model with high precision might be preferred in scenarios where false positives are extremely costly (e.g., blocking legitimate customer transactions), whereas a model with high recall might be prioritized when missing fraudulent transactions has severe consequences. The optimal balance between precision and recall depends on the specific context and risk tolerance of the financial institution.
Deployment Challenges and Considerations, The Role of AI in Real-Time Fraud Detection in Financial Transactions
Deploying an AI-powered fraud detection system in a real-world financial environment presents several unique challenges.
- Real-time processing requirements: The system must process transactions with minimal latency to avoid disrupting the flow of legitimate transactions. This necessitates efficient algorithms and infrastructure capable of handling high transaction volumes.
- Data drift: Fraudulent techniques evolve constantly, requiring the model to be retrained periodically to adapt to new patterns. Regular monitoring and retraining are essential to maintain the system’s accuracy.
- Scalability and infrastructure: The system must be scalable to handle fluctuations in transaction volumes and adapt to the growing size of the data. This often involves cloud-based solutions and robust infrastructure.
- Explainability and interpretability: Understanding why the model makes specific decisions is crucial for building trust and compliance. Employing explainable AI (XAI) techniques can help to enhance transparency and accountability.
- Security and privacy: Protecting sensitive financial data is paramount. The system must adhere to strict security protocols and privacy regulations to prevent data breaches and unauthorized access.
- Regulatory compliance: The system must comply with relevant financial regulations and industry standards. This involves rigorous testing, auditing, and documentation.
For instance, a major bank might deploy a fraud detection system using a distributed architecture across multiple servers to ensure high availability and low latency. Regular model retraining using fresh transaction data would be implemented to adapt to evolving fraud patterns. Furthermore, the system’s decisions would be logged and monitored to maintain transparency and comply with regulatory requirements.
Addressing Ethical and Regulatory Concerns

Source: neilsahota.com
The rise of AI in fraud detection, while promising increased accuracy and efficiency, introduces significant ethical and regulatory challenges. Balancing the need for robust security with the protection of individual rights and the prevention of unfair outcomes is paramount. Ignoring these concerns could lead to widespread distrust and ultimately undermine the effectiveness of these systems.
AI-driven fraud detection systems, while powerful, are not immune to the biases present in the data they are trained on. This can lead to discriminatory outcomes, unfairly targeting specific demographic groups. Furthermore, the lack of transparency in some AI algorithms makes it difficult to understand how decisions are made, raising concerns about accountability and fairness. Addressing these issues requires a multifaceted approach encompassing both technical solutions and regulatory frameworks.
Bias Mitigation Strategies in AI Fraud Detection
Mitigating bias requires a proactive approach starting with data collection. Careful curation of training datasets to ensure representation across diverse demographics is crucial. Techniques like data augmentation, where underrepresented groups’ data is artificially increased, can help balance the dataset. Furthermore, employing algorithmic fairness techniques during model development, such as fairness-aware machine learning algorithms, can help minimize discriminatory outcomes. Regular audits and monitoring of the system’s performance across different demographic groups are essential to identify and address emerging biases. For example, a system trained primarily on data from one region might misclassify transactions from another region as fraudulent due to differences in spending patterns. Addressing this would involve incorporating data from diverse geographical locations during training.
The Regulatory Landscape of AI in Finance
The use of AI in finance is subject to a complex and evolving regulatory landscape. Regulations like GDPR in Europe and CCPA in California place significant emphasis on data privacy and the right to explanation. Financial institutions are required to ensure transparency and accountability in their AI systems, demonstrating how decisions are made and mitigating potential biases. Compliance requirements often necessitate rigorous testing and validation of AI models, ensuring they meet specific accuracy and fairness standards. Failure to comply with these regulations can result in substantial penalties. For instance, a financial institution using an AI system that violates GDPR could face hefty fines and reputational damage.
Responsible and Ethical Use of AI in Fraud Detection
Responsible use of AI in fraud detection necessitates prioritizing transparency and explainability. This means designing systems that provide clear and understandable explanations for their decisions, allowing for human oversight and recourse in case of errors. Furthermore, incorporating human-in-the-loop mechanisms, where human experts review and validate AI-generated decisions, can significantly reduce the risk of biased or inaccurate outcomes. Continuous monitoring and evaluation of the system’s performance, coupled with regular updates and retraining to address emerging threats and biases, are also critical for maintaining ethical standards. For example, a bank could use AI to flag potentially fraudulent transactions, but have human analysts review those flags before taking action, ensuring accuracy and preventing false positives that could harm legitimate customers.
Future Trends and Challenges
The landscape of AI-powered fraud detection is constantly evolving, driven by the ingenuity of fraudsters and the relentless advancement of artificial intelligence. While AI offers powerful tools to combat financial crime, significant hurdles remain, requiring ongoing innovation and adaptation. The future of this field hinges on addressing these challenges and embracing emerging trends.
The next five years will witness a significant shift in how AI tackles real-time fraud detection. Expect to see a move towards more sophisticated, adaptive systems that learn and evolve alongside the ever-changing tactics of fraudsters. This evolution will be characterized by increased reliance on explainable AI, advanced analytics, and a greater emphasis on data privacy and security.
Explainable AI (XAI) and Increased Transparency
The “black box” nature of many AI models has been a major concern in financial applications. Explainable AI (XAI) aims to address this by providing insights into how a model arrives at its decisions. This is crucial for building trust, complying with regulations, and identifying potential biases in the system. Imagine a scenario where an AI flags a transaction as fraudulent. With XAI, the system can explain its reasoning, highlighting specific features or patterns that triggered the alert. This transparency allows for human oversight and helps prevent wrongful accusations. The adoption of XAI will be key to widespread acceptance and integration of AI in fraud detection.
Advanced Analytics and Predictive Modeling
Beyond basic anomaly detection, advanced analytics will play a more significant role. This includes techniques like graph analytics to identify complex fraud networks and predictive modeling to anticipate future fraud patterns based on historical data and emerging trends. For example, by analyzing social media data and news articles, an AI system could predict potential scams or identify individuals at higher risk of becoming victims. This proactive approach allows for preventative measures and reduces the overall impact of fraudulent activities. The integration of these advanced analytical techniques will allow for more accurate and timely fraud detection.
Challenges in AI-Powered Fraud Detection
Several challenges persist in effectively utilizing AI for real-time fraud detection. One key challenge is the constant evolution of fraud techniques. Fraudsters are adept at adapting their methods to bypass detection systems. This requires AI models to be continuously retrained and updated to remain effective. Another challenge is the need for high-quality, labeled data to train these models. Obtaining sufficient data that accurately represents various fraud types and scenarios can be difficult and expensive. Furthermore, ensuring data privacy and complying with regulations like GDPR is crucial, requiring careful consideration of data handling practices. Finally, the computational cost associated with processing massive datasets in real-time can be substantial, necessitating efficient algorithms and infrastructure.
Projected Evolution of AI in Fraud Detection (Next Five Years)
Imagine a visual representation: A timeline spanning five years, starting with a relatively simple AI system (represented by a single, smaller circle) focused primarily on rule-based anomaly detection. As the timeline progresses, the circle grows larger and more complex, incorporating additional layers representing advanced analytics, XAI capabilities, and integration with diverse data sources (e.g., social media, IoT devices). The color of the circle gradually shifts from a muted grey to a vibrant blue, symbolizing the increasing sophistication and effectiveness of the system. By year five, the circle is significantly larger and more intricate, showing multiple interconnected nodes representing seamless integration with other systems and proactive fraud prevention capabilities. This visual represents the expected increase in sophistication, adaptability, and predictive power of AI in fraud detection over the next five years, driven by advancements in XAI, advanced analytics, and the integration of diverse data sources.
Final Thoughts
In a world of increasingly sophisticated financial fraud, AI isn’t just a helpful tool – it’s a necessity. While challenges remain in areas like bias mitigation and regulatory compliance, the potential of AI to revolutionize real-time fraud detection is undeniable. From enhanced accuracy and speed to proactive threat identification, the future of secure financial transactions hinges on harnessing the power of artificial intelligence responsibly and ethically. The evolution is happening now, and it’s shaping a safer financial landscape for everyone.