
The Role of AI in Detecting Financial Fraud in Real-Time – AI’s Role in Detecting Financial Fraud in Real-Time: Forget dusty ledgers and manual checks – the future of fraud prevention is here, and it’s powered by artificial intelligence. With financial crime evolving at lightning speed, traditional methods are struggling to keep up. Enter AI, a game-changer offering real-time analysis and predictive capabilities that could revolutionize how we fight fraud. But it’s not a magic bullet; implementing AI-driven systems presents its own set of hurdles. This deep dive explores the potential, the pitfalls, and the future of AI in the fight against financial fraud.
From sophisticated machine learning algorithms sniffing out anomalies in transaction patterns to NLP deciphering suspicious emails, AI is transforming fraud detection. We’ll unpack the different techniques, the crucial data preprocessing steps, and the ethical considerations that must be addressed. We’ll also look at how to train, evaluate, and deploy these AI models effectively, ensuring accuracy and compliance. Get ready to unravel the complexities of this cutting-edge field.
Introduction to Real-Time Financial Fraud Detection

Source: hackread.com
Financial fraud is a constantly evolving threat, impacting individuals, businesses, and the global economy on an unprecedented scale. Traditional fraud detection methods, often relying on rule-based systems and historical data analysis, struggle to keep pace with the sophistication and speed of modern fraud schemes. These legacy systems frequently miss subtle anomalies and react too slowly to prevent significant losses. The sheer volume of transactions processed daily by financial institutions further exacerbates the problem, making manual review impractical and inefficient. This is where the transformative power of Artificial Intelligence (AI) comes into play.
AI offers the potential to revolutionize real-time fraud detection by leveraging advanced algorithms and machine learning techniques to analyze vast datasets, identify complex patterns, and predict fraudulent activities with significantly greater accuracy and speed than traditional methods. By analyzing transactional data in real-time, AI systems can flag suspicious activities instantly, enabling immediate intervention and minimizing financial losses. This proactive approach represents a crucial shift from reactive, post-incident investigations.
Challenges in Implementing AI-Driven Fraud Detection Systems, The Role of AI in Detecting Financial Fraud in Real-Time
Implementing AI-driven fraud detection systems, however, presents several significant challenges. The need for high-quality, labeled data to train effective AI models is paramount. Gathering and annotating such data is a time-consuming and expensive process. Furthermore, maintaining the accuracy and effectiveness of these models requires continuous retraining and adaptation as fraud techniques evolve. The complexity of AI algorithms can also make it difficult to understand and interpret their decisions, raising concerns about transparency and explainability. Data privacy and security are also crucial considerations, as AI systems often handle sensitive personal and financial information. Finally, the integration of AI systems into existing financial infrastructure can be complex and costly, requiring significant technical expertise and investment. For example, a large bank might struggle to integrate a new AI system with legacy systems that were not designed for real-time data processing and analysis. Successfully navigating these challenges is crucial for realizing the full potential of AI in combating financial fraud.
AI Techniques for Real-Time Fraud Detection: The Role Of AI In Detecting Financial Fraud In Real-Time
Real-time fraud detection demands speed and accuracy, a challenge perfectly suited to the capabilities of Artificial Intelligence. AI algorithms can sift through massive datasets of transactions, identifying subtle patterns and anomalies that would be impossible for humans to spot in a timely manner. This allows for immediate flagging of potentially fraudulent activity, minimizing financial losses and protecting both businesses and consumers.
Machine Learning Algorithms for Fraud Detection
Several machine learning algorithms excel at real-time fraud detection, each with its strengths and weaknesses. The choice of algorithm depends heavily on the specific type of fraud being targeted and the available data. Below is a comparison of three prominent approaches.
| Algorithm | Strengths | Weaknesses | Application Examples |
|---|---|---|---|
| Anomaly Detection | Effective at identifying unusual transactions that deviate significantly from established patterns; requires minimal labeled data. | Can generate false positives if the definition of “normal” is not well-defined; struggles with evolving fraud patterns. | Detecting unusual spending patterns on credit cards; identifying rogue transactions in high-volume payment systems. |
| Supervised Learning (e.g., Logistic Regression, Random Forest) | High accuracy when sufficient labeled data is available; provides interpretable results in some cases. | Requires a large, well-labeled dataset for training; can be computationally expensive for very large datasets. | Classifying fraudulent versus legitimate transactions based on historical data; predicting the likelihood of loan defaults. |
| Deep Learning (e.g., Recurrent Neural Networks, Convolutional Neural Networks) | Can handle complex, high-dimensional data; excels at identifying intricate patterns and relationships. | Requires significant computational resources; requires large amounts of data for training; can be difficult to interpret. | Analyzing complex transaction networks to detect money laundering; identifying fraudulent images or documents. |
Natural Language Processing for Fraud Detection
Natural Language Processing (NLP) is a powerful tool for analyzing unstructured textual data, revealing hidden clues of fraudulent activity. By processing transaction descriptions, emails, and chat logs, NLP algorithms can identify suspicious s, phrases, or sentiment indicative of fraud. For example, an email containing urgent requests for wire transfers to unfamiliar accounts might trigger an alert. NLP can also help detect inconsistencies between the narrative provided and the actual transaction details.
Behavioral Biometrics for Fraud Detection
AI-powered systems are increasingly utilizing behavioral biometrics to enhance fraud detection. These systems analyze subtle variations in user behavior, such as typing patterns, mouse movements, and scrolling habits. Deviations from a user’s established baseline can indicate unauthorized access or fraudulent activity. For instance, a sudden change in typing speed or mouse movements during an online banking session might trigger an authentication challenge. This approach adds an extra layer of security beyond traditional password-based authentication, making it harder for fraudsters to impersonate legitimate users.
Data Sources and Preprocessing for AI-Based Fraud Detection
Real-time fraud detection relies heavily on the quality and quantity of data fed into AI models. The more comprehensive and clean the data, the more accurate and effective the fraud detection system becomes. This section explores the crucial data sources and the preprocessing pipeline necessary to transform raw data into a format suitable for AI algorithms.
The effectiveness of AI in real-time fraud detection hinges on access to diverse and high-quality data. This data needs careful preparation to ensure the AI models can accurately identify fraudulent activities. A robust preprocessing pipeline is essential for achieving this accuracy.
Data Sources for Real-Time Fraud Detection
Real-time fraud detection systems leverage a variety of data sources to build a comprehensive picture of transactions and user behavior. These sources provide different perspectives, allowing the AI to identify patterns indicative of fraud that might be missed by looking at a single data point.
- Transaction Data: This is the cornerstone of fraud detection. Transaction data includes details like the amount, time, location, merchant, and payment method used. For example, a sudden surge in high-value transactions from an unusual location might flag a potential fraud case. This data is typically stored in transactional databases and can be streamed in real-time.
- Customer Data: Understanding customer behavior is crucial. Data points like the customer’s purchase history, demographics, contact information, and account activity provide context for transactions. For instance, a sudden change in purchase patterns or location might indicate account compromise.
- Network Data: Network data, such as IP addresses, device IDs, and geolocation data, can help identify suspicious activities originating from unusual networks or locations. This is particularly useful for detecting fraudulent activities involving compromised devices or botnets.
- Third-Party Data: Integrating data from external sources, like credit bureaus or fraud databases, can significantly enhance fraud detection capabilities. This can provide additional risk scores or identify known fraudulent actors.
Data Preprocessing Pipeline
Raw data is rarely ready for direct use in AI models. It often contains missing values, outliers, and inconsistencies that can significantly impact model performance. A well-designed preprocessing pipeline addresses these issues systematically.
The data preprocessing pipeline typically involves several stages. These stages are crucial for ensuring that the data is consistent, complete, and suitable for AI model training and inference. Ignoring this step can lead to inaccurate and unreliable results.
- Data Cleaning: This initial step involves handling missing values, removing duplicates, and correcting inconsistencies. Techniques like imputation (filling in missing values), outlier removal, and data standardization are commonly used.
- Data Transformation: This step involves converting data into a format suitable for AI models. This may involve scaling numerical features, encoding categorical variables, and creating new features from existing ones. For example, transforming transaction amounts into logarithmic values can help normalize their distribution.
- Feature Engineering: This crucial step involves creating new features that capture relevant patterns and relationships in the data. For instance, creating a feature representing the frequency of transactions within a specific time window can be highly informative.
- Data Reduction: High-dimensional data can negatively impact model performance and training time. Techniques like principal component analysis (PCA) can reduce the dimensionality of the data while preserving important information.
Data Cleaning Techniques
Several techniques are used to clean and prepare data for AI models. The choice of technique depends on the nature of the data and the specific issues encountered.
- Handling Missing Values: Techniques include imputation using mean, median, mode, or more sophisticated methods like k-Nearest Neighbors (KNN) imputation. The best approach depends on the nature of the missing data and the distribution of the variable.
- Outlier Detection and Treatment: Outliers can significantly skew model performance. Techniques like the IQR method, Z-score method, or DBSCAN can identify outliers. Treatment options include removal, capping, or transformation.
- Data Standardization/Normalization: Scaling features to a similar range helps prevent features with larger values from dominating the model. Common methods include Min-Max scaling and Z-score standardization.
- Data Consistency Checks: Verifying data consistency across different sources and ensuring data types are correct is crucial. This often involves checks for data integrity and validation against predefined rules.
Model Training, Evaluation, and Deployment

Source: aitimejournal.com
AI’s real-time fraud detection is a game-changer, instantly flagging suspicious transactions. This rapid analysis is just one example of machine learning’s power; its applications extend far beyond finance, as explored in this insightful article on The Future of Machine Learning in Automated Customer Support. Ultimately, the ability of AI to learn and adapt makes it crucial for preventing financial crime and enhancing various other sectors.
Training an AI model for real-time fraud detection is a crucial step, involving careful data handling and rigorous evaluation to ensure its effectiveness in a live environment. This process goes beyond simply feeding data into an algorithm; it requires strategic decisions about data splitting, hyperparameter tuning, and model selection to optimize performance and minimize false positives and negatives.
Data Splitting and Hyperparameter Tuning
The initial step involves splitting the dataset into training, validation, and testing sets. The training set is used to teach the model, the validation set helps tune hyperparameters (settings that control the learning process), and the testing set provides an unbiased evaluation of the final model’s performance on unseen data. A common split is 70% for training, 15% for validation, and 15% for testing. Hyperparameter tuning involves experimenting with different settings (e.g., learning rate, number of layers in a neural network) to find the optimal configuration that maximizes the model’s accuracy on the validation set. This is often done using techniques like grid search or randomized search, systematically exploring different parameter combinations. For example, in a fraud detection model using a gradient boosting machine, tuning the learning rate and the number of trees can significantly impact the model’s ability to distinguish fraudulent transactions.
Model Selection
Choosing the right model is critical. Various algorithms are suitable for fraud detection, including logistic regression, support vector machines (SVMs), decision trees, random forests, and neural networks. The choice depends on the characteristics of the data and the specific requirements of the application. For instance, if interpretability is crucial, a decision tree or a logistic regression model might be preferred, while for complex, high-dimensional data, a neural network might offer superior performance. Each model has its strengths and weaknesses, and selecting the best one often involves comparing their performance on the validation set using appropriate metrics.
Model Evaluation Metrics
Evaluating a fraud detection model requires careful consideration of various metrics, each providing a different perspective on its performance. Understanding these metrics is essential to make informed decisions about model selection and deployment.
- Precision: The proportion of correctly identified fraudulent transactions out of all transactions flagged as fraudulent. A high precision indicates a low rate of false positives (flagging legitimate transactions as fraudulent). For example, a precision of 90% means that out of every 100 transactions flagged as fraudulent, 90 are actually fraudulent.
- Recall (Sensitivity): The proportion of correctly identified fraudulent transactions out of all actual fraudulent transactions. High recall indicates a low rate of false negatives (failing to identify fraudulent transactions). A recall of 85% means that the model correctly identifies 85 out of every 100 fraudulent transactions.
- F1-Score: The harmonic mean of precision and recall. It provides a balanced measure of both metrics. A high F1-score indicates good performance in both identifying fraudulent transactions and minimizing false positives and negatives. The F1-score is particularly useful when dealing with imbalanced datasets (where fraudulent transactions are significantly fewer than legitimate ones).
- AUC (Area Under the ROC Curve): Measures the model’s ability to distinguish between fraudulent and legitimate transactions across different thresholds. A higher AUC (closer to 1) indicates better discriminatory power. The ROC curve plots the true positive rate (recall) against the false positive rate at various classification thresholds. An AUC of 0.9 indicates excellent discrimination, meaning the model is very good at separating fraudulent from legitimate transactions.
Model Deployment
Deploying a trained model for real-time fraud detection involves integrating it into the existing transaction processing system. This typically involves deploying the model to a server or cloud platform that can handle real-time requests. The model receives transaction data as input, predicts whether each transaction is fraudulent or not, and triggers appropriate actions (e.g., blocking the transaction, flagging it for review). Monitoring the model’s performance in the production environment is crucial to ensure it continues to perform effectively and adapt to changing patterns of fraudulent activity. Regular retraining with updated data is necessary to maintain accuracy and address concept drift (changes in the relationship between input variables and the target variable over time). For example, a real-time fraud detection system might use a microservice architecture, allowing for easy scaling and updates to the model as needed. Regular performance monitoring and retraining ensures that the system remains effective in identifying new fraud patterns.
Ethical Considerations and Regulatory Compliance
Deploying AI for real-time fraud detection offers incredible potential, but it also raises significant ethical and legal questions. Balancing the need for robust security with the protection of individual rights is a crucial challenge for financial institutions. Failing to address these concerns can lead to reputational damage, legal repercussions, and erosion of public trust.
The use of AI in finance necessitates careful consideration of potential biases embedded within the algorithms, ensuring fairness in application, and protecting the privacy of sensitive customer data. Regulatory bodies worldwide are increasingly focusing on the ethical and responsible use of AI, demanding transparency and accountability from organizations leveraging these powerful technologies.
Bias and Fairness in AI-Driven Fraud Detection
AI models learn from the data they are trained on. If this data reflects existing societal biases, the AI system will likely perpetuate and even amplify these biases. For example, an AI trained on historical fraud data that disproportionately flags transactions from certain demographic groups might unfairly target those groups for further scrutiny, even if they are not actually engaging in fraudulent activity. This can lead to discriminatory outcomes and negatively impact individuals and communities. Mitigating bias requires careful data curation, algorithmic auditing, and ongoing monitoring of the system’s performance across different demographic segments. Techniques like fairness-aware machine learning are being developed to address these challenges.
Data Privacy and Security in AI-Based Fraud Detection Systems
AI-driven fraud detection systems often rely on vast amounts of sensitive personal data, including transaction history, location data, and even biometric information. Protecting this data from unauthorized access and misuse is paramount. Compliance with regulations like GDPR (General Data Protection Regulation) in Europe and CCPA (California Consumer Privacy Act) in the US is crucial. This involves implementing robust security measures, obtaining informed consent from data subjects, and ensuring data minimization – only collecting and processing the data necessary for fraud detection. Data anonymization and encryption techniques also play a vital role in safeguarding privacy.
Regulatory Compliance and Best Practices
Financial institutions must adhere to a complex web of regulations governing data privacy, anti-money laundering (AML), and consumer protection. These regulations vary by jurisdiction but generally require transparency in AI systems, explainability of decisions, and the ability to audit the system’s performance. Best practices include establishing clear ethical guidelines for AI development and deployment, conducting regular audits to assess for bias and fairness, and implementing robust mechanisms for redress in cases of wrongful accusations. Building a culture of ethical AI within the organization is also essential, involving training employees on responsible AI practices and fostering open communication about ethical dilemmas. Examples of regulatory bodies actively shaping the landscape include the Financial Conduct Authority (FCA) in the UK and the Office of the Comptroller of the Currency (OCC) in the US, which are increasingly issuing guidance on the responsible use of AI in finance.
Future Trends and Challenges
The landscape of real-time financial fraud detection is constantly evolving, driven by the ingenuity of fraudsters and the rapid advancements in technology. While AI has revolutionized the field, significant challenges remain, and emerging technologies offer both opportunities and new complexities. Understanding these future trends and proactively addressing the challenges is crucial for maintaining the integrity of financial systems.
The increasing sophistication of fraudulent activities necessitates a continuous evolution of detection methods. Simply relying on current AI models is insufficient; a proactive approach that anticipates future threats and leverages emerging technologies is essential for staying ahead of the curve.
Emerging Technologies Enhancing Fraud Detection
The integration of blockchain technology, for instance, offers a significant potential for enhancing transparency and traceability in financial transactions. Its immutable ledger system can provide a robust audit trail, making it harder for fraudsters to manipulate data or conceal their activities. Imagine a scenario where every transaction is recorded on a distributed, tamper-proof ledger – tracing the origin and flow of funds becomes significantly easier, allowing for faster identification of suspicious patterns. Quantum computing, while still in its nascent stages, holds the promise of exponentially faster processing power, enabling AI models to analyze vast datasets and identify complex fraud patterns far more efficiently than current systems. This could lead to the development of AI systems capable of detecting subtle anomalies that would otherwise go unnoticed. The potential of quantum computing in cryptography also presents a double-edged sword: while it could break current encryption methods, it could also lead to the development of new, unbreakable encryption, thus enhancing security.
Limitations of Current AI-Based Systems and Potential Solutions
Current AI-based fraud detection systems face several limitations. One key challenge is the problem of data imbalance – the sheer volume of legitimate transactions dwarfs the number of fraudulent ones, making it difficult for AI models to accurately learn and identify fraudulent activities. Techniques like oversampling minority classes or using anomaly detection algorithms can mitigate this issue. Another limitation is the “adversarial” nature of fraud. Fraudsters constantly adapt their methods, rendering existing models ineffective over time. Continuous model retraining and adaptation using techniques like reinforcement learning are needed to counter this dynamic threat landscape. Finally, the “black box” nature of some AI models makes it difficult to understand their decision-making process, hindering explainability and trust. Developing more transparent and interpretable AI models, such as those based on decision trees or rule-based systems, is crucial for building confidence and ensuring regulatory compliance.
Impact of AI on the Future of Financial Crime Prevention
The future of financial crime prevention is inextricably linked to the continued development and deployment of AI. AI’s ability to analyze massive datasets in real-time, identify complex patterns, and adapt to evolving threats makes it an indispensable tool in the fight against financial fraud. We can anticipate a future where AI systems are not merely reactive but proactive, predicting and preventing fraud before it even occurs. This could involve using AI to identify and flag high-risk individuals or transactions based on behavioral patterns or predictive modeling. Moreover, AI could significantly streamline regulatory compliance by automating processes and providing real-time insights into potential violations. However, it’s crucial to acknowledge the ethical considerations and potential biases embedded within AI systems, ensuring fairness and accountability in their deployment. The development of robust ethical guidelines and regulatory frameworks will be paramount to harnessing the full potential of AI while mitigating its risks.
Wrap-Up
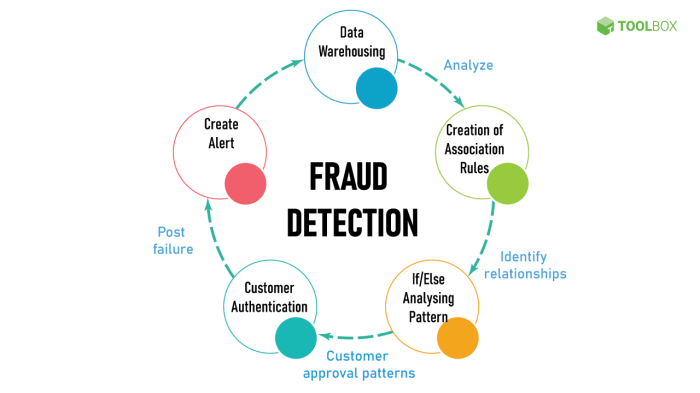
Source: website-files.com
The fight against financial fraud is an ongoing battle, and AI is emerging as a powerful weapon in our arsenal. While challenges remain – data biases, regulatory hurdles, and the ever-evolving tactics of fraudsters – the potential benefits of real-time AI-driven detection are undeniable. By understanding the intricacies of AI algorithms, data preprocessing, ethical considerations, and deployment strategies, we can build more robust and effective systems to safeguard our financial systems. The future of financial security might just depend on it. Let’s get to work.