
How Machine Learning is Shaping the Future of Predictive Analytics? It’s a game-changer, folks. Forget dusty crystal balls; we’re talking algorithms predicting everything from your next purchase to the next pandemic. This isn’t just about crunching numbers; it’s about understanding the future, one data point at a time. We’ll dive into how machine learning is revolutionizing predictive analytics, exploring its core techniques, real-world applications, and the ethical considerations that come with this powerful technology. Get ready to have your mind blown (and maybe a little freaked out).
From predicting disease outbreaks to optimizing supply chains, machine learning is rewriting the rules of prediction. We’ll uncover how algorithms like regression, classification, and clustering are used across industries, from healthcare and finance to marketing and logistics. We’ll also tackle the thorny issues of bias, data privacy, and the need for explainable AI. Buckle up, it’s going to be a wild ride.
The Evolution of Predictive Analytics
Predictive analytics, the art of forecasting future outcomes based on historical data, has undergone a dramatic transformation, fueled by advancements in computing power and the rise of big data. From its humble beginnings in statistical modeling to its current state leveraging sophisticated machine learning algorithms, the journey has been nothing short of revolutionary. This evolution has profoundly impacted various sectors, enabling more accurate predictions and informed decision-making.
Predictive analytics’ evolution is a story of increasing sophistication and power, marked by several key phases. Initially, it relied heavily on traditional statistical methods, which, while effective in their time, faced limitations in handling complex, high-dimensional datasets. The arrival of machine learning, however, marked a paradigm shift, unlocking new possibilities for prediction accuracy and insight generation.
Traditional Statistical Methods versus Modern Machine Learning
Traditional statistical methods, such as regression analysis and time series modeling, were the cornerstone of predictive analytics for decades. These methods rely on established mathematical formulas and statistical assumptions to model relationships between variables and predict future outcomes. For example, linear regression could be used to predict house prices based on size, location, and age. However, these methods often struggle with non-linear relationships, high dimensionality, and noisy data. They also require significant expertise to interpret and apply correctly.
Machine learning, on the other hand, employs algorithms that learn patterns from data without explicit programming. Techniques like decision trees, support vector machines, and neural networks can handle complex, non-linear relationships and high-dimensional datasets far more effectively than traditional methods. For instance, a neural network could analyze vast amounts of customer data (purchase history, demographics, browsing behavior) to predict customer churn with greater accuracy than a simpler regression model. This allows for more nuanced and accurate predictions.
Limitations of Traditional Methods and the Machine Learning Advantage
Traditional statistical methods often fall short when faced with massive datasets, intricate relationships between variables, and the presence of noise or missing data. Their reliance on strong assumptions about data distribution can lead to inaccurate predictions if these assumptions are violated. Furthermore, interpreting the results of complex statistical models can be challenging, requiring significant statistical expertise.
Machine learning algorithms, particularly deep learning models, excel in handling these challenges. They can automatically learn complex patterns from large, noisy datasets, requiring less reliance on strict assumptions. They also offer improved scalability, making them suitable for analyzing massive datasets that would overwhelm traditional methods. While interpretability can still be a concern with some machine learning models (like deep neural networks), techniques are being developed to address this limitation.
The Impact of Increased Computing Power and Big Data
The exponential growth in computing power and the availability of massive datasets (big data) have been pivotal in driving the evolution of predictive analytics. Previously computationally intensive algorithms, such as neural networks, are now readily applicable thanks to advancements in processing power and parallel computing. Big data provides the raw material for training these sophisticated models, enabling them to learn more intricate patterns and make more accurate predictions. For example, the ability to analyze millions of customer transactions allows for hyper-personalized recommendations and targeted marketing campaigns, something impossible with limited data and processing power. The combination of increased computing power and big data has truly unlocked the potential of machine learning in predictive analytics.
Core Machine Learning Techniques in Predictive Analytics
Source: cloudfront.net
Machine learning’s predictive power is revolutionizing various sectors, offering insights previously unimaginable. This extends even to real estate, where transparency and security are paramount; check out this insightful piece on how blockchain is changing the game: The Impact of Blockchain on the Real Estate Market and Transactions to see how these technologies intertwine. Ultimately, these advancements feed back into more accurate and efficient machine learning models for predictive analytics across the board.
Predictive analytics relies heavily on machine learning algorithms to uncover patterns and make predictions from data. These algorithms, ranging from simple linear regression to complex deep learning models, are the engines driving the future of predictive power. Understanding their strengths and weaknesses is crucial for effectively applying them to various real-world problems.
Core Machine Learning Algorithms for Prediction, How Machine Learning is Shaping the Future of Predictive Analytics
The selection of an appropriate machine learning algorithm depends heavily on the nature of the prediction task (classification, regression, clustering) and the characteristics of the data. Here are five core algorithms frequently employed:
| Algorithm | Strengths | Weaknesses | Typical Applications |
|---|---|---|---|
| Linear Regression | Simple to understand and implement; computationally efficient; provides interpretable results. | Assumes a linear relationship between variables; sensitive to outliers; performs poorly with non-linear data. | Predicting house prices based on size and location; forecasting sales revenue based on advertising spend; estimating crop yields based on rainfall and temperature. |
| Logistic Regression | Efficient; provides probability estimates; readily interpretable; suitable for binary and multi-class classification. | Assumes a linear decision boundary; sensitive to outliers; may not perform well with highly non-linear data. | Spam detection; credit risk assessment; medical diagnosis (e.g., predicting the likelihood of a disease). |
| Decision Trees | Easy to understand and visualize; handles both numerical and categorical data; requires little data preprocessing. | Prone to overfitting; can be unstable (small changes in data can lead to large changes in the tree structure). | Customer segmentation; fraud detection; medical diagnosis. |
| Support Vector Machines (SVM) | Effective in high-dimensional spaces; versatile (can be used for both classification and regression); relatively memory efficient. | Computationally expensive for large datasets; the choice of kernel function can significantly impact performance; less interpretable than some other algorithms. | Image classification; text categorization; bioinformatics. |
| K-Means Clustering | Simple and efficient; relatively easy to implement; scales well to large datasets. | Requires specifying the number of clusters (k) beforehand; sensitive to initial cluster centers; struggles with non-spherical clusters. | Customer segmentation; document clustering; anomaly detection. |
Feature Engineering and its Importance
Feature engineering, the process of selecting, transforming, and creating new features from raw data, is a critical step in building accurate predictive models. Poorly engineered features can lead to poor model performance, regardless of the algorithm used. Effective feature engineering can significantly improve model accuracy by making the underlying patterns in the data more apparent to the algorithm.
Feature Engineering Techniques
Several techniques enhance features. For example, *one-hot encoding* transforms categorical variables (like colors: red, blue, green) into numerical representations (e.g., red=[1,0,0], blue=[0,1,0], green=[0,0,1]). *Scaling* normalizes numerical features to a similar range, preventing features with larger values from dominating the model. *Feature interaction* creates new features by combining existing ones (e.g., combining age and income to create a “wealth” feature). *Polynomial features* add non-linearity to the model by creating features that are powers of existing features (e.g., creating x², x³ from x).
Handling Different Data Types
Machine learning models handle various data types differently. Linear regression and logistic regression work directly with numerical data. Decision trees can handle both numerical and categorical data directly. For text data, techniques like TF-IDF (Term Frequency-Inverse Document Frequency) are used to convert text into numerical representations suitable for algorithms. Time series data requires specialized algorithms like ARIMA (Autoregressive Integrated Moving Average) or Recurrent Neural Networks (RNNs) to capture temporal dependencies. For instance, predicting stock prices utilizes time series analysis techniques, while sentiment analysis of customer reviews uses text processing and classification algorithms.
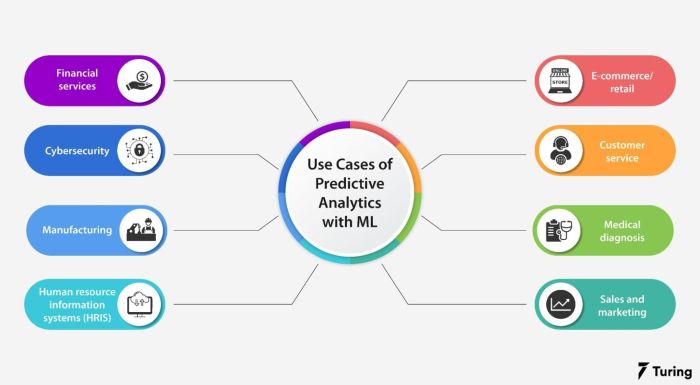
Applications of Machine Learning in Predictive Analytics Across Industries: How Machine Learning Is Shaping The Future Of Predictive Analytics
Machine learning is no longer a futuristic concept; it’s a powerful tool reshaping industries by enhancing predictive analytics. Its ability to identify patterns, make predictions, and automate complex processes is revolutionizing how businesses operate and make decisions, leading to increased efficiency, profitability, and improved customer experiences. This section explores how machine learning is transforming various sectors through its application in predictive analytics.
Machine Learning in Healthcare
The healthcare industry is ripe for disruption through the power of predictive analytics fueled by machine learning. By analyzing vast datasets of patient information, including medical history, genetic data, and lifestyle factors, machine learning algorithms can identify patterns and predict potential health risks with remarkable accuracy. This allows for proactive interventions and personalized treatment plans, ultimately improving patient outcomes and reducing healthcare costs.
- Disease Prediction: Machine learning models can analyze patient data to predict the likelihood of developing specific diseases, such as heart disease, cancer, or diabetes, allowing for early detection and preventative measures.
- Personalized Medicine: By analyzing a patient’s unique genetic makeup and medical history, machine learning can help doctors tailor treatment plans to individual needs, maximizing effectiveness and minimizing side effects. For instance, predicting the best drug dosage for a specific patient based on their genetic profile.
- Improved Diagnostics: Machine learning algorithms can analyze medical images (X-rays, MRIs, CT scans) to assist radiologists in detecting anomalies and making more accurate diagnoses, leading to faster and more effective treatment.
Machine Learning in Finance
The financial industry relies heavily on accurate predictions to manage risk, detect fraud, and optimize investment strategies. Machine learning provides a powerful set of tools to analyze complex financial data and identify subtle patterns that might otherwise go unnoticed.
Imagine a scenario where a bank uses a machine learning model to analyze transaction data in real-time. The model is trained to identify unusual patterns, such as unusually large withdrawals or transactions from unusual locations, that might indicate fraudulent activity. If a suspicious transaction is flagged, the system automatically alerts the bank’s fraud detection team, allowing them to investigate and prevent potential losses. This system significantly reduces the risk of fraud and protects both the bank and its customers. This is just one example; machine learning is also used for credit scoring, algorithmic trading, and risk management.
Machine Learning in Marketing and Customer Relationship Management
In the competitive world of marketing and customer relationship management (CRM), understanding customer behavior is paramount. Machine learning empowers businesses to analyze customer data and predict future actions, leading to more effective marketing campaigns and improved customer loyalty.
- Customer Churn Prediction: By analyzing customer data, including purchase history, website activity, and customer service interactions, machine learning models can predict which customers are most likely to churn. This allows businesses to proactively address concerns and retain valuable customers.
- Targeted Advertising: Machine learning algorithms can analyze customer data to identify specific customer segments and tailor advertising campaigns to their individual preferences and needs. This increases the effectiveness of advertising spending and improves conversion rates.
- Personalized Recommendations: E-commerce platforms utilize machine learning to analyze customer purchase history and browsing behavior to provide personalized product recommendations, increasing sales and improving customer satisfaction. Amazon’s recommendation engine is a prime example.
Machine Learning in Supply Chain Management and Logistics
Supply chain management and logistics involve complex networks of suppliers, manufacturers, distributors, and retailers. Predictive analytics powered by machine learning can significantly improve efficiency and reduce costs by optimizing various aspects of the supply chain.
- Demand Forecasting: Machine learning algorithms can analyze historical sales data, market trends, and external factors to predict future demand for products. This allows businesses to optimize inventory levels, reduce waste, and avoid stockouts.
- Inventory Optimization: By analyzing data on inventory levels, sales forecasts, and lead times, machine learning can help businesses optimize their inventory management strategies, minimizing storage costs and preventing stockouts or overstocking.
- Route Optimization: Machine learning can analyze real-time traffic data, weather conditions, and other factors to optimize delivery routes, reducing transportation costs and delivery times. This is particularly useful for companies with large delivery fleets.
Challenges and Ethical Considerations
Predictive analytics, while incredibly powerful, isn’t without its pitfalls. The increasing reliance on machine learning models introduces a complex web of ethical concerns and practical challenges that need careful consideration. Failing to address these issues can lead to flawed predictions, unfair outcomes, and a erosion of public trust.
Bias in Machine Learning Models and Mitigation Strategies
Machine learning models are only as good as the data they are trained on. If that data reflects existing societal biases – for example, gender bias in hiring data or racial bias in criminal justice data – the model will inevitably perpetuate and even amplify those biases. This can lead to discriminatory outcomes, denying opportunities to certain groups and reinforcing existing inequalities. Mitigation strategies involve careful data curation, employing techniques like data augmentation to balance datasets, and using algorithmic fairness tools to detect and correct for bias in model outputs. Regular audits and independent evaluations of models are also crucial to ensure fairness and prevent unintended discrimination. For instance, a loan application algorithm trained on historical data might unfairly deny loans to applicants from specific zip codes simply because those areas have historically had higher default rates, regardless of the individual applicant’s creditworthiness.
Data Privacy and Security in Predictive Analytics
The power of predictive analytics hinges on access to vast amounts of data, often including sensitive personal information. This raises significant concerns about data privacy and security. Breaches can have devastating consequences, leading to identity theft, financial loss, and reputational damage. Robust security measures, including encryption, access controls, and anonymization techniques, are essential to protect sensitive data. Furthermore, adherence to data privacy regulations like GDPR and CCPA is paramount. Transparency with data subjects about how their data is being used is also crucial to building trust and fostering ethical data practices. Consider the scenario of a healthcare provider using predictive analytics to identify patients at high risk of developing a specific disease. The accuracy of the predictions relies on access to sensitive medical records, demanding stringent security protocols to prevent unauthorized access and maintain patient confidentiality.
Interpretability and Explainability of Machine Learning Models
Many advanced machine learning models, particularly deep learning models, are often described as “black boxes.” Their decision-making processes are opaque, making it difficult to understand why a model arrived at a particular prediction. This lack of transparency can be problematic, especially in high-stakes applications like healthcare or finance, where understanding the reasoning behind a prediction is critical. Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) aim to improve model explainability by providing insights into the factors that contribute to a model’s predictions. However, these methods themselves have limitations and ongoing research is needed to develop more robust and reliable explainability techniques. For example, a model predicting loan defaults might flag an applicant as high-risk. Without understanding the factors driving this prediction, it’s impossible to determine whether the model is making a fair and accurate assessment or perpetuating bias.
Ethical Implications of Predictive Analytics in Hiring
Imagine a company using a machine learning model to screen job applicants. The model is trained on historical hiring data, which, unbeknownst to the company, reflects a bias against female candidates for certain roles. The model, therefore, systematically ranks female applicants lower than equally qualified male applicants. This results in fewer women being invited for interviews, perpetuating gender inequality within the company. This scenario highlights the ethical dangers of relying solely on predictive analytics in hiring without careful consideration of potential biases and a thorough understanding of the model’s decision-making process. Implementing fairness-aware algorithms, regular audits of the model’s performance, and human oversight are essential to ensure ethical and unbiased hiring practices.
The Future Landscape of Predictive Analytics with Machine Learning

Source: cloudfront.net
Predictive analytics, already a powerful tool, is poised for an even more transformative future thanks to the rapid advancements in machine learning. The next decade will witness a dramatic shift in how we leverage data to anticipate trends, optimize processes, and make better decisions across all sectors. This evolution will be driven by several key factors, including the maturation of existing techniques and the emergence of entirely new ones.
Emerging Trends in Machine Learning
Deep learning, a subset of machine learning inspired by the structure and function of the brain, is already revolutionizing predictive analytics. Its ability to analyze complex, unstructured data like images and text opens up possibilities previously unimaginable. For example, deep learning models are now used to predict equipment failures in manufacturing plants with remarkable accuracy, leading to proactive maintenance and reduced downtime. Reinforcement learning, another exciting area, allows algorithms to learn through trial and error, making it ideal for dynamic environments where strategies need to adapt constantly. Imagine self-driving cars, where reinforcement learning algorithms constantly refine their driving strategies based on real-world experiences. These advanced techniques will continue to improve the accuracy, speed, and adaptability of predictive models.
The Impact of Quantum Computing
Quantum computing, while still in its early stages, holds the potential to revolutionize predictive analytics. Its ability to process vast amounts of data exponentially faster than classical computers could unlock solutions to problems currently intractable. For instance, optimizing complex supply chains or accurately forecasting highly volatile markets, tasks currently challenging even for the most powerful supercomputers, could become routine with quantum-powered predictive analytics. While widespread adoption is still years away, the potential impact is undeniable, promising to drastically improve the accuracy and speed of predictions across a wide range of applications.
Predictions for Machine Learning Transformation Across Sectors
The next 5-10 years will see a significant transformation in various sectors due to the increasing power of machine learning in predictive analytics.
- Healthcare: Personalized medicine will become more prevalent, with predictive models tailoring treatments based on individual patient data, leading to improved outcomes and reduced healthcare costs. For example, AI-powered diagnostic tools will become more accurate and widely accessible, allowing for earlier detection of diseases.
- Finance: Fraud detection will become significantly more sophisticated, using machine learning to identify and prevent fraudulent transactions in real-time. Algorithmic trading will also become even more prevalent, with AI-powered systems making trading decisions at speeds and scales impossible for humans.
- Retail: Hyper-personalization will reach new heights, with retailers using predictive models to anticipate customer needs and preferences, leading to more effective marketing campaigns and increased customer loyalty. Inventory management will also become more efficient, reducing waste and optimizing supply chains.
- Manufacturing: Predictive maintenance will become standard practice, using machine learning to anticipate equipment failures and prevent costly downtime. This will lead to increased efficiency and reduced production costs.
The Need for Skilled Professionals
The increasing reliance on machine learning in predictive analytics creates a significant demand for skilled professionals. Data scientists, machine learning engineers, and predictive analytics specialists are crucial for developing, implementing, and maintaining these complex systems. Universities and training institutions need to adapt their curricula to meet this growing demand, ensuring a pipeline of talent equipped to handle the challenges and opportunities presented by this rapidly evolving field. The development of robust training programs, focusing on both theoretical understanding and practical application, is essential to ensure the successful integration of machine learning into various sectors. Furthermore, fostering collaboration between academia and industry will be key to bridging the gap between theoretical advancements and real-world applications.
Final Conclusion

Source: ksolves.com
So, there you have it – a glimpse into the fascinating world of machine learning and predictive analytics. The future is being shaped by algorithms, and while there are challenges and ethical considerations to navigate, the potential benefits are undeniable. From personalized medicine to more efficient supply chains, the impact is already being felt across numerous sectors. As machine learning continues to evolve, so too will our ability to predict and shape the future. The only question is, are you ready?