
How Machine Learning is Revolutionizing Data Science? Forget dusty spreadsheets and manual calculations – the data game just got a serious upgrade. Machine learning isn’t just a buzzword; it’s the engine driving a data science revolution, automating tasks, uncovering hidden insights, and making predictions with unprecedented accuracy. This isn’t your grandpappy’s data analysis; we’re talking algorithms that learn, adapt, and constantly improve, making complex data problems seem, well, less complex.
From predicting customer behavior to detecting fraud, machine learning is transforming how we interact with data. We’ll dive deep into the algorithms, the processes, and the real-world impact, showing you exactly how this tech is changing the game across various industries. Get ready to level up your data literacy.
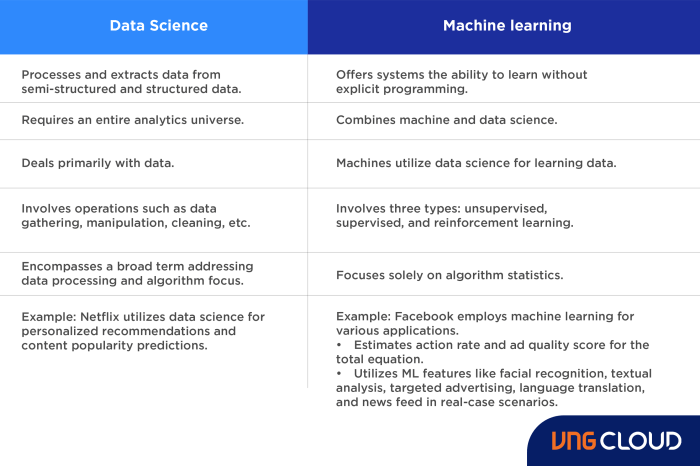
The Evolving Landscape of Data Science
Data science, once a realm dominated by statistical modeling and manual data manipulation, has undergone a dramatic transformation thanks to the rise of machine learning. The shift has been nothing short of revolutionary, empowering data scientists with tools and techniques previously unimaginable. This evolution has fundamentally altered how we approach data analysis, prediction, and decision-making.
Traditional Data Science Methods
Before the widespread adoption of machine learning, data science heavily relied on statistical methods and manual feature engineering. Data scientists meticulously cleaned, transformed, and analyzed data using techniques like linear regression, logistic regression, and hypothesis testing. The process was often time-consuming and required significant domain expertise to extract meaningful insights. Interpreting results was largely based on statistical significance and expert judgment, limiting the ability to handle complex, high-dimensional datasets. Visualization tools were simpler, and predictive modeling capabilities were limited by the complexity of the models that could be manually constructed and interpreted.
Machine Learning’s Impact on Data Science
Machine learning has fundamentally reshaped the core functionalities of data science. Instead of relying solely on explicit programming and pre-defined rules, machine learning algorithms learn patterns and relationships directly from data. This automation reduces the need for extensive manual feature engineering and allows for the analysis of much larger and more complex datasets. The ability to handle unstructured data, such as images and text, has also dramatically expanded the scope of data science applications. Furthermore, the predictive power of machine learning models often surpasses that of traditional statistical methods, leading to more accurate forecasts and improved decision-making.
Examples of Enhanced Data Science Tasks
Several data science tasks, once incredibly challenging, are now relatively straightforward thanks to machine learning. For instance, image recognition, previously requiring complex image processing techniques and handcrafted features, is now readily accomplished using convolutional neural networks (CNNs). Similarly, natural language processing (NLP) tasks, such as sentiment analysis and machine translation, have seen remarkable advancements due to the development of powerful recurrent neural networks (RNNs) and transformer models. Fraud detection, a crucial task in finance, has also been significantly improved by machine learning algorithms that can identify subtle patterns indicative of fraudulent activity. Recommender systems, a staple of e-commerce platforms, rely heavily on machine learning to provide personalized recommendations to users.
Comparison of Traditional and Machine Learning Approaches
| Method | Traditional Approach | Machine Learning Approach | Advantages of ML Approach |
|---|---|---|---|
| Regression | Linear Regression, Polynomial Regression (requiring feature engineering) | Support Vector Regression, Random Forest Regression | Handles non-linear relationships, automatic feature selection, higher accuracy |
| Classification | Logistic Regression, Discriminant Analysis (requires careful feature selection) | Support Vector Machines, Naive Bayes, Neural Networks | Handles high dimensionality, complex relationships, better generalization |
| Clustering | K-means, Hierarchical Clustering (sensitive to initial conditions and data scaling) | DBSCAN, Gaussian Mixture Models | Robustness to noise and outliers, automatic determination of cluster number (in some cases) |
| Anomaly Detection | Statistical process control (requires defining thresholds) | One-class SVM, Isolation Forest | Automatic anomaly identification, handles complex patterns |
Machine Learning Algorithms Transforming Data Analysis
The rise of machine learning has fundamentally reshaped data science, empowering analysts to extract insights from data at an unprecedented scale and complexity. No longer confined to simple statistical analyses, data scientists now leverage powerful algorithms to build predictive models, uncover hidden patterns, and automate decision-making processes. This section explores some of the key algorithms driving this transformation.
Linear Regression
Linear regression is a fundamental supervised learning algorithm used to model the relationship between a dependent variable and one or more independent variables. It assumes a linear relationship, meaning the change in the dependent variable is proportional to the change in the independent variables. This simplicity makes it highly interpretable, allowing data scientists to understand the impact of each independent variable on the outcome. For example, a real estate company might use linear regression to predict house prices based on factors like size, location, and age. The model’s coefficients would reveal the relative importance of each factor in determining price. This allows for targeted pricing strategies and better investment decisions.
Decision Trees
Decision trees are another popular supervised learning algorithm used for both classification and regression tasks. They create a tree-like model of decisions and their possible consequences, allowing for easy visualization and interpretation of the decision-making process. Each branch represents a decision based on a feature, and each leaf node represents an outcome. For instance, a bank might use a decision tree to assess loan applications, considering factors like credit score, income, and debt-to-income ratio. The tree visually shows the path leading to approval or rejection, highlighting the crucial factors influencing the decision. This transparency makes decision trees valuable for regulatory compliance and explaining model predictions to stakeholders.
Neural Networks
Neural networks, a cornerstone of deep learning, are complex algorithms inspired by the structure and function of the human brain. They consist of interconnected nodes (neurons) organized in layers, allowing them to learn highly non-linear relationships in data. Their ability to handle massive datasets and complex patterns makes them particularly effective in image recognition, natural language processing, and other challenging data science tasks. For example, a medical imaging company might use a convolutional neural network (a type of neural network) to detect cancerous tumors in medical scans with high accuracy, far exceeding the capabilities of traditional image analysis techniques. This leads to earlier diagnosis and improved patient outcomes.
Supervised vs. Unsupervised Learning
Supervised learning algorithms, like linear regression and decision trees, are trained on labeled data, meaning the data includes both input features and the corresponding output or target variable. Unsupervised learning algorithms, on the other hand, work with unlabeled data, aiming to discover hidden patterns and structures without prior knowledge of the outcomes. In data science, supervised learning is often used for prediction tasks (e.g., predicting customer churn), while unsupervised learning is employed for exploratory data analysis, clustering, and dimensionality reduction. For example, a retail company might use k-means clustering (an unsupervised learning technique) to segment customers into distinct groups based on their purchasing behavior, allowing for targeted marketing campaigns.
Hypothetical Scenario: Fraud Detection with Neural Networks
Imagine a financial institution facing a rising tide of fraudulent credit card transactions. They possess a vast dataset of past transactions, including details like transaction amount, location, time, and customer profile information. A neural network, specifically a recurrent neural network (RNN) capable of processing sequential data, could be trained on this historical data to identify patterns indicative of fraudulent activity. The RNN would learn complex temporal relationships between transactions, recognizing anomalies such as unusual spending patterns or geographically dispersed transactions within a short timeframe. By analyzing the sequence of transactions, the RNN could accurately flag potentially fraudulent transactions for further investigation, significantly reducing financial losses and improving security.
Impact on Data Preprocessing and Feature Engineering
Machine learning is no longer just a tool for building predictive models; it’s fundamentally reshaping the entire data science pipeline. This transformation is particularly evident in data preprocessing and feature engineering, two traditionally labor-intensive stages that now benefit significantly from automation and intelligent algorithms. The ability to leverage machine learning at these foundational steps leads to more efficient workflows, improved model accuracy, and ultimately, better insights from data.
Data preprocessing, the crucial initial step of cleaning and transforming raw data, often involves tedious tasks like handling missing values, dealing with outliers, and standardizing data formats. Feature engineering, the process of selecting, transforming, and creating new features from existing ones, is equally demanding, requiring domain expertise and creative problem-solving to identify features that best predict the target variable. Machine learning offers powerful techniques to automate and optimize both these processes.
Automated Data Preprocessing
Machine learning algorithms can automate several data preprocessing tasks, significantly reducing the time and effort required. For instance, instead of manually imputing missing values using simple methods like mean or median imputation, algorithms like k-Nearest Neighbors (k-NN) can intelligently predict missing values based on the values of nearby data points. Similarly, machine learning can identify and handle outliers more effectively than manual inspection, using techniques like isolation forests or one-class SVMs to detect anomalies. Automated data type conversion and data normalization are also readily achievable using machine learning, ensuring consistent data formats for downstream analysis. These automated processes not only save time but also reduce the risk of human error, leading to cleaner and more reliable datasets.
Machine Learning in Feature Engineering and Selection
Machine learning plays a pivotal role in both feature engineering and selection. Instead of relying solely on human intuition, algorithms can automatically generate new features from existing ones using techniques like polynomial features, interaction terms, or feature crosses. For example, in a real estate dataset, an algorithm might automatically create a new feature representing the product of square footage and number of bedrooms, capturing the combined effect of these two features on house price. Furthermore, machine learning methods like recursive feature elimination (RFE) or LASSO regularization can effectively select the most relevant features from a large set, improving model efficiency and preventing overfitting. This automated feature selection reduces the dimensionality of the data, simplifying the model and improving its interpretability.
Examples of Automated Feature Engineering Improving Model Accuracy and Efficiency
Consider a fraud detection model. Manually engineering features might involve creating rules based on transaction amounts, locations, and times. However, a machine learning approach could automatically discover more complex and subtle patterns, such as identifying unusual sequences of transactions or correlations between seemingly unrelated features. This automated approach often leads to a significant improvement in the model’s accuracy and its ability to detect previously unseen fraudulent activities. Similarly, in image recognition, automated feature extraction using convolutional neural networks (CNNs) has dramatically improved the accuracy of object detection and classification tasks compared to manually designed features. The CNNs learn intricate features directly from the raw image data, bypassing the need for manual feature engineering.
Workflow Diagram: Machine Learning Enhanced Data Preprocessing and Feature Engineering
Imagine a diagram depicting a workflow. The first stage, “Data Collection and Initial Cleaning,” involves gathering raw data and performing basic checks for inconsistencies. This feeds into “Automated Preprocessing,” where machine learning algorithms handle missing values, outliers, and data normalization. The next stage, “Automated Feature Engineering,” uses machine learning to generate new features and select the most relevant ones. This refined dataset then proceeds to “Model Training and Evaluation,” where a machine learning model is trained and its performance is assessed. Finally, the process concludes with “Model Deployment and Monitoring,” where the trained model is deployed for real-world applications and its performance is continuously monitored. This iterative workflow highlights how machine learning is seamlessly integrated throughout the entire data preprocessing and feature engineering process, leading to improved model performance and efficiency.
Revolutionizing Data Visualization and Interpretation
Machine learning is no longer just crunching numbers; it’s transforming how we *see* and understand those numbers. Gone are the days of static bar charts and confusing scatter plots. Machine learning is injecting dynamism and insight into data visualization, allowing us to uncover hidden patterns and make more informed decisions than ever before. This revolution is fueled by algorithms that can automatically identify key features, create compelling visuals, and even offer insightful interpretations of complex datasets.
Data visualization, traditionally a manual and often time-consuming process, is now being significantly accelerated and enhanced by machine learning. Algorithms can analyze vast datasets, identify the most relevant variables, and automatically generate visualizations that highlight key trends and outliers. This automated process not only saves time and resources but also allows data scientists to explore more possibilities and uncover insights that might otherwise be missed. Furthermore, machine learning enables the creation of interactive and dynamic visualizations that adapt to the user’s exploration, providing a deeper and more intuitive understanding of the data.
Automated Visualization Generation
Machine learning algorithms can automatically generate various visualizations based on the characteristics of the dataset. For instance, an algorithm might identify a clustering pattern in a dataset and automatically generate a scatter plot highlighting these clusters, color-coded for easy interpretation. Alternatively, if a dataset shows a strong temporal trend, the algorithm might automatically generate a time-series plot to illustrate the evolution of the data over time. This automation removes the burden of manual selection and allows for rapid exploration of various visualization possibilities. Consider a scenario where a retail company uses machine learning to analyze customer purchase data. The algorithm might automatically generate a heatmap showing the geographical distribution of sales, instantly revealing regional trends and informing targeted marketing campaigns.
Pattern Identification and Anomaly Detection
Machine learning algorithms excel at identifying subtle patterns and anomalies that might be missed by the human eye. Techniques like dimensionality reduction (e.g., t-SNE, UMAP) can project high-dimensional data into lower dimensions, revealing hidden structures and clusters. Anomaly detection algorithms can identify unusual data points that deviate significantly from the norm, flagging potential fraud, equipment malfunctions, or other critical events. For example, in fraud detection, machine learning can identify unusual transaction patterns that indicate fraudulent activity, even if those patterns are not immediately obvious to a human analyst. This capability is crucial in various domains, from finance to healthcare, where the timely detection of anomalies can have significant consequences.
Advanced Visualization Techniques, How Machine Learning is Revolutionizing Data Science
Several advanced visualization techniques are powered by machine learning. These include:
- Interactive dashboards: Machine learning algorithms can power interactive dashboards that allow users to explore data dynamically, filtering and sorting data in real-time and generating visualizations on demand.
- Self-organizing maps (SOMs): These neural networks create low-dimensional representations of high-dimensional data, revealing underlying structures and patterns. They are particularly useful for visualizing complex datasets with many variables.
- Network graphs: Machine learning can be used to analyze relationships between data points and generate network graphs that visually represent these connections, providing insights into complex systems and relationships.
Visualization Tools and Techniques
A range of tools and techniques are commonly used in conjunction with machine learning for data visualization:
- Tableau: A popular business intelligence tool that integrates with machine learning libraries for advanced data analysis and visualization.
- Power BI: Microsoft’s business analytics service, offering similar capabilities to Tableau with strong integration with other Microsoft products.
- Python libraries (Matplotlib, Seaborn, Plotly): These libraries provide extensive capabilities for creating static and interactive visualizations, often used in conjunction with machine learning libraries like scikit-learn and TensorFlow.
- R libraries (ggplot2, lattice): Similar to Python libraries, these provide powerful visualization capabilities within the R statistical computing environment.
Applications Across Diverse Industries
Machine learning’s impact extends far beyond the realm of theoretical data science; it’s actively reshaping entire industries, driving efficiency, and revolutionizing decision-making processes. Its ability to analyze vast datasets and identify complex patterns unlocks opportunities previously unimaginable, leading to significant economic benefits and improved outcomes across diverse sectors. Let’s delve into how this transformative technology is impacting some key players.
Healthcare
The healthcare industry is undergoing a massive transformation thanks to machine learning. From diagnostics to personalized medicine, ML algorithms are improving patient care and streamlining operations. For instance, machine learning models are being trained on medical images (X-rays, MRIs, CT scans) to detect diseases like cancer at earlier stages, significantly improving treatment outcomes and survival rates. This early detection leads to more effective and less invasive treatments, reducing healthcare costs in the long run. Furthermore, machine learning helps predict patient readmission rates, allowing hospitals to proactively manage patient care and reduce unnecessary hospital stays. This improves resource allocation and ultimately leads to cost savings and better patient experiences.
Finance
The financial sector is another prime example of machine learning’s transformative power. Fraud detection is a critical application where ML excels. By analyzing transaction patterns and identifying anomalies, machine learning algorithms can flag potentially fraudulent activities in real-time, preventing significant financial losses for banks and their customers. Beyond fraud detection, machine learning is used in algorithmic trading, predicting market trends, and managing risk. These applications lead to more efficient trading strategies, improved portfolio management, and ultimately, higher returns for investors. The ability to make faster, more data-driven decisions significantly reduces financial risk and enhances profitability.
Retail
In the competitive world of retail, machine learning is proving to be a game-changer. Personalized recommendations, driven by analyzing customer purchase history and browsing behavior, enhance customer experience and drive sales. By understanding individual preferences, retailers can offer targeted promotions and product suggestions, increasing customer engagement and loyalty. Furthermore, machine learning optimizes supply chain management by predicting demand, optimizing inventory levels, and improving logistics. This reduces waste, minimizes storage costs, and ensures that products are available when and where customers need them. The overall impact is increased efficiency, reduced operational costs, and higher profitability.
| Industry | Specific Application | Impact on Efficiency | Impact on Decision-Making |
|---|---|---|---|
| Healthcare | Early disease detection (cancer, etc.) using medical image analysis | Improved diagnostic accuracy, reduced treatment time and costs | Data-driven decisions on treatment plans, resource allocation, and patient management |
| Finance | Fraud detection through anomaly detection in transaction data | Reduced financial losses, improved security measures | Real-time risk assessment, improved investment strategies, optimized resource allocation |
| Retail | Personalized product recommendations based on customer behavior | Increased sales conversion rates, optimized inventory management | Data-driven decisions on marketing campaigns, product assortment, and supply chain optimization |
Addressing Challenges and Ethical Considerations: How Machine Learning Is Revolutionizing Data Science
Source: com.vn
The transformative power of machine learning in data science is undeniable, but its implementation isn’t without hurdles. Navigating these challenges responsibly requires a keen awareness of potential pitfalls and a commitment to ethical practices. Ignoring these aspects risks not only flawed results but also significant societal harm.
Data bias, computational costs, and the inherent “black box” nature of some algorithms are just a few of the obstacles that need careful consideration. Furthermore, the ethical implications of using machine learning in decision-making processes, particularly those with far-reaching consequences, demand rigorous scrutiny and proactive mitigation strategies.
Data Bias and Algorithmic Fairness
Bias in data sets is a major concern. Machine learning models are trained on data, and if that data reflects existing societal biases (e.g., gender, racial, socioeconomic), the model will likely perpetuate and even amplify those biases. For example, a facial recognition system trained primarily on images of white faces might perform poorly on images of people with darker skin tones, leading to inaccurate and potentially discriminatory outcomes. This necessitates careful data curation, pre-processing techniques to identify and mitigate bias, and ongoing monitoring of model performance across diverse demographics. Algorithmic fairness is not just a technical problem; it’s a societal imperative.
Computational Cost and Scalability
Training sophisticated machine learning models, especially deep learning models, can be computationally expensive. This requires significant computing power and energy, which can be a barrier for smaller organizations or projects with limited resources. Furthermore, scaling these models to handle massive datasets presents significant logistical and infrastructure challenges. Strategies like using cloud computing resources, optimizing algorithms, and employing techniques like federated learning can help address these scalability concerns.
Interpretability and Explainability of Models
Many powerful machine learning algorithms, particularly deep neural networks, are often described as “black boxes.” This means it can be difficult to understand how the model arrives at its predictions. This lack of transparency can be problematic in high-stakes applications like healthcare or finance, where understanding the reasoning behind a decision is crucial. Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) are being developed to improve model interpretability, making it easier to understand and trust the predictions made by complex algorithms.
Ethical Implications of Machine Learning in Decision-Making
The use of machine learning in decision-making raises several ethical questions. For example, algorithms used in loan applications, hiring processes, or criminal justice could inadvertently discriminate against certain groups if not carefully designed and monitored. Transparency and accountability are paramount. It is crucial to establish clear guidelines and regulations to ensure that machine learning systems are used responsibly and ethically, minimizing the potential for harm and bias. Regular audits and independent evaluations of these systems are essential to maintain trust and accountability.
Mitigating Bias and Ensuring Responsible Use
Several methods can be employed to mitigate bias and ensure responsible use of machine learning algorithms. These include: carefully curating and pre-processing data to identify and address biases; employing techniques like data augmentation to create more representative datasets; using fairness-aware algorithms that explicitly consider fairness constraints during model training; implementing rigorous testing and validation procedures to identify and correct biases; and fostering transparency and explainability in the model’s decision-making process. Furthermore, continuous monitoring and evaluation are essential to identify and address emerging biases over time. This is an ongoing process that requires collaboration between data scientists, ethicists, and policymakers.
Best Practices for Ethical Data Science
Best practices for ethical data science incorporating machine learning involve a multi-faceted approach. This includes establishing clear ethical guidelines and principles for data collection, use, and sharing; promoting transparency and accountability in the development and deployment of machine learning systems; ensuring data privacy and security; fostering collaboration and communication among stakeholders; and providing ongoing education and training on ethical considerations in data science. Furthermore, regularly auditing models for bias and ensuring they adhere to established ethical guidelines is crucial. Companies like Google and Microsoft have published their own AI principles, illustrating a growing commitment to responsible AI development. These principles often emphasize fairness, accountability, and transparency.
Conclusive Thoughts
In short, the marriage of machine learning and data science is a game-changer. It’s not just about faster processing; it’s about unlocking a deeper understanding of complex data, leading to better decisions and innovative solutions. While challenges remain – bias, ethical considerations, and computational costs – the potential benefits are undeniable. As machine learning continues to evolve, expect even more breakthroughs, making data-driven decision-making smarter, faster, and more impactful than ever before. The future is data-driven, and it’s powered by machine learning.
Machine learning’s impact on data science is massive, enabling faster, more accurate insights. This power extends to security, where the rise of biometric authentication is a game-changer; learn more about this exciting field by checking out this article on How Biometric Authentication is Transforming Security. Ultimately, these advancements, fueled by machine learning, are creating a safer and more efficient digital world.