
The Role of Machine Learning in Predicting Natural Disasters is no longer a futuristic fantasy; it’s rapidly becoming a crucial tool in safeguarding lives and property. Traditional methods, relying heavily on historical data and expert judgment, often fall short in accurately forecasting the unpredictable nature of these events. Machine learning, with its ability to analyze vast datasets and identify complex patterns, offers a powerful new approach, enhancing predictive accuracy and enabling more effective disaster preparedness. From predicting earthquake aftershocks to forecasting hurricane trajectories, the potential applications are vast and transformative.
This exploration delves into the heart of this transformative technology, examining the data sources, algorithms, and evaluation metrics that underpin its success. We’ll explore real-world case studies showcasing the impact of machine learning on disaster response, while also acknowledging the inherent challenges and exciting future possibilities this field presents.
Introduction to Machine Learning in Disaster Prediction
Predicting natural disasters has always been a high-stakes game of probability. Historically, reliance on past patterns and statistical models offered a limited view, often leaving communities vulnerable and unprepared. While traditional methods provided some forecasting ability, they struggled to account for the complex interplay of environmental factors and the inherent unpredictability of nature. The advent of machine learning, however, is revolutionizing this field, offering more accurate, timely, and nuanced predictions.
Machine learning algorithms, particularly deep learning models, excel at identifying intricate patterns and correlations within massive datasets that would be impossible for humans to discern. This allows for the incorporation of diverse data sources – from satellite imagery and sensor readings to social media posts and historical weather records – leading to significantly improved predictive capabilities. Unlike traditional methods that often rely on simplified models and assumptions, machine learning adapts and learns from new data, constantly refining its predictive accuracy over time.
Limitations of Traditional Disaster Prediction Methods
Traditional methods for predicting natural disasters, such as statistical modeling and physical models, often rely on simplified representations of complex systems. These methods may struggle to accurately capture the non-linear relationships and chaotic behavior inherent in many natural phenomena. For instance, predicting the exact path and intensity of a hurricane using solely historical data and physical models can be challenging due to the influence of subtle atmospheric changes. Furthermore, the data required for these models can be limited, geographically sparse, or of inconsistent quality, affecting the reliability of the predictions. The lack of real-time data integration further hampers their effectiveness in providing timely warnings.
Machine Learning’s Enhanced Predictive Capabilities
Machine learning algorithms overcome many limitations of traditional methods by leveraging the power of big data and advanced computational techniques. They can analyze vast amounts of data from diverse sources, including high-resolution satellite imagery, seismic sensor networks, weather radar data, and social media activity, to identify subtle patterns and predict events with greater accuracy and lead time. For example, convolutional neural networks (CNNs) can process satellite imagery to detect subtle changes in land surface temperature or vegetation patterns that might indicate an impending wildfire. Similarly, recurrent neural networks (RNNs) can analyze time-series data like seismic activity to predict the likelihood and magnitude of earthquakes. The ability of these algorithms to learn complex relationships and adapt to new data makes them invaluable tools for improving disaster prediction.
Applications of Machine Learning in Disaster Prediction
Machine learning is applicable across a wide range of natural disasters. For instance, in earthquake prediction, machine learning models can analyze seismic data to identify precursory signals and predict the location and magnitude of future earthquakes, potentially improving early warning systems. In the case of hurricanes, machine learning algorithms can process satellite imagery and weather data to predict the storm’s path, intensity, and potential landfall with greater accuracy than traditional models. Wildfires can be predicted by analyzing satellite imagery to detect changes in vegetation, temperature, and humidity, while flood prediction can be improved by incorporating rainfall data, river level measurements, and soil moisture information. Even predicting landslides can benefit from machine learning, using topographical data, rainfall patterns, and geological information to identify high-risk areas. The versatility of machine learning makes it a powerful tool for enhancing preparedness and mitigation efforts across diverse disaster scenarios. For example, the successful prediction of the 2011 Tohoku earthquake and tsunami, while not entirely reliant on machine learning at the time, highlighted the potential of using advanced algorithms to integrate diverse data sources for more comprehensive risk assessment.
Data Sources and Preprocessing for Machine Learning Models: The Role Of Machine Learning In Predicting Natural Disasters
Predicting natural disasters effectively relies heavily on the quality and quantity of data fed into machine learning models. Getting this right is crucial – garbage in, garbage out, as they say. This section explores the diverse data sources used and the essential preprocessing steps needed to make this data useful for prediction.
Machine learning algorithms thrive on structured, clean data. However, the raw data related to natural disasters is often messy, incomplete, and inconsistent. This means significant effort is required to prepare the data before it can be used to train and evaluate predictive models. This involves several key steps, from data collection and cleaning to feature engineering and handling missing values.
Key Data Sources for Natural Disaster Prediction
Natural disaster prediction draws upon a wide range of data sources, each offering unique insights into different aspects of impending events. These sources are often combined to create a more comprehensive picture.
Imagine trying to predict a hurricane’s path without satellite imagery showing its size and strength. Or forecasting an earthquake without geological sensor data detecting subtle shifts in the Earth’s crust. The combination of these diverse sources allows for more accurate and timely predictions.
Machine learning’s ability to crunch vast datasets is revolutionizing natural disaster prediction, offering earlier warnings and potentially saving lives. This predictive power is intrinsically linked to the broader impact of big data, as explored in this insightful article: The Role of Big Data in Shaping the Future of Business. Ultimately, the more data we analyze, the more accurately machine learning can forecast these devastating events, leading to better preparedness and response strategies.
| Data Source | Disaster Type | Suitability | Example |
|---|---|---|---|
| Satellite Imagery | Floods, Wildfires, Hurricanes | High | High-resolution images from satellites like Landsat and Sentinel can provide crucial information on land surface changes, vegetation health, and water levels, aiding in flood and wildfire prediction. Hurricane intensity and track can be monitored via infrared imagery. |
| Sensor Data (Seismic, Meteorological, etc.) | Earthquakes, Volcanoes, Tsunamis, Floods, Severe Weather | High | Seismic sensors detect ground movements preceding earthquakes, while meteorological sensors monitor atmospheric pressure, temperature, and humidity, providing vital data for weather forecasting and flood prediction. |
| Historical Records (Weather Data, Disaster Events) | All Disaster Types | Medium | Long-term weather records help establish patterns and probabilities of extreme weather events. Historical disaster records identify past events, locations, and impacts, informing risk assessments. |
| Social Media Data | Floods, Wildfires, Earthquakes | Medium | Real-time updates from social media can provide valuable information on the ground during a disaster, supplementing official reports and improving situational awareness, though this data needs careful filtering and verification. |
Data Cleaning and Preprocessing
Before a machine learning model can effectively utilize the collected data, it needs to be cleaned and preprocessed. This often involves dealing with missing values, handling outliers, and transforming data into a suitable format for the chosen algorithm.
For example, imagine a dataset with missing rainfall data for a specific region. Simple imputation techniques, such as replacing missing values with the average rainfall of neighboring regions, could be used. Alternatively, more sophisticated methods, like K-Nearest Neighbors, might be employed to estimate missing values based on similar data points.
Challenges in Data Acquisition and Quality
Gathering and preparing data for natural disaster prediction presents several significant hurdles. Data quality can be inconsistent, with missing values, errors, and biases affecting the accuracy of predictions. Data availability also varies across different regions and disaster types, hindering the development of comprehensive models.
For instance, reliable historical data might be scarce in developing countries, limiting the ability to train robust models for those regions. Furthermore, biases in historical data can lead to inaccurate predictions, such as underestimating the risk in areas historically overlooked.
Machine Learning Algorithms for Disaster Prediction
Predicting natural disasters is a complex task, but machine learning offers powerful tools to analyze vast datasets and identify patterns indicative of impending events. The choice of algorithm depends heavily on the specific disaster type, the available data, and the desired prediction outcome – whether it’s predicting the likelihood of an event (classification), estimating its intensity (regression), or identifying similar disaster-prone areas (clustering).
The effectiveness of different machine learning approaches in disaster prediction varies significantly. Understanding these strengths and weaknesses is crucial for selecting the most appropriate model for a given scenario.
Regression Algorithms for Disaster Prediction
Regression algorithms are ideal for predicting continuous variables, such as the intensity of an earthquake or the amount of rainfall preceding a flood. They model the relationship between predictor variables (e.g., seismic activity, soil moisture) and the target variable (e.g., earthquake magnitude, rainfall amount). Linear regression, a fundamental approach, assumes a linear relationship between variables. However, more complex relationships often require non-linear regression techniques like Support Vector Regression (SVR) or Random Forest Regression. SVR excels in handling high-dimensional data and non-linear relationships, while Random Forest Regression leverages the power of multiple decision trees to improve accuracy and robustness. A weakness of regression models is their sensitivity to outliers and the assumption of a specific relationship between variables which may not always hold true in complex natural phenomena. For instance, predicting the exact magnitude of an earthquake using regression might be less accurate than predicting the probability of an earthquake exceeding a certain magnitude (which is a classification task).
Classification Algorithms for Disaster Prediction
Classification algorithms predict categorical outcomes, making them suitable for tasks such as predicting whether a wildfire will occur in a specific region or whether a hurricane will make landfall. Commonly used algorithms include Logistic Regression, Support Vector Machines (SVM), and Random Forest Classification. Logistic Regression is straightforward and interpretable, but its accuracy might be limited for complex datasets. SVM’s are powerful in handling high-dimensional data and non-linear relationships, but require careful parameter tuning. Random Forest Classification, similar to its regression counterpart, benefits from ensemble learning, improving prediction accuracy and stability. However, the “black box” nature of some of these algorithms (especially complex ensemble methods) can make it difficult to understand the reasoning behind their predictions, which is a critical consideration in high-stakes disaster management. For example, classifying regions as high, medium, or low risk for landslides using a Random Forest model might yield high accuracy but lack a clear explanation for the classification of specific regions.
Clustering Algorithms for Disaster Prediction
Clustering algorithms group similar data points together, which can be useful for identifying areas with similar characteristics prone to specific disasters. K-means clustering is a popular choice due to its simplicity and speed, but it requires specifying the number of clusters beforehand. Hierarchical clustering provides a hierarchical structure of clusters, offering a more nuanced understanding of data relationships. DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is effective in identifying clusters of arbitrary shapes and handling outliers, making it suitable for complex geographical data. The major challenge with clustering is the subjective interpretation of the resulting clusters and the lack of direct predictive power compared to regression and classification. For instance, clustering historical earthquake data could reveal regions with similar geological characteristics, but it wouldn’t directly predict the timing or magnitude of future earthquakes. It’s more of a tool for risk assessment and resource allocation.
Algorithm Selection Flowchart
A flowchart for algorithm selection would begin with defining the prediction task (classification, regression, or clustering). This branches to considering the type of data (continuous, categorical, spatial), followed by an evaluation of the data size and complexity. Based on these factors, a suitable algorithm is chosen (e.g., logistic regression for binary classification with smaller datasets, Random Forest for complex classification, SVR for regression with non-linear relationships). Finally, model performance is evaluated using appropriate metrics (e.g., accuracy, precision, recall for classification; RMSE, MAE for regression) and the model is refined or a different algorithm selected if necessary. The flowchart would visually represent these decision points and pathways, ultimately guiding the selection of the optimal machine learning algorithm.
Examples of Algorithms in Real-World Applications
Several real-world examples showcase the application of machine learning algorithms in disaster prediction. For instance, the use of Support Vector Machines (SVM) for landslide susceptibility mapping in mountainous regions, Random Forest for predicting wildfire risk in California based on historical fire data and environmental factors, and the application of neural networks for forecasting tsunami propagation using oceanographic data. These applications highlight the versatility of different algorithms in addressing various disaster prediction challenges. The choice of algorithm is always context-dependent, balancing accuracy, interpretability, and computational cost.
Model Evaluation and Validation
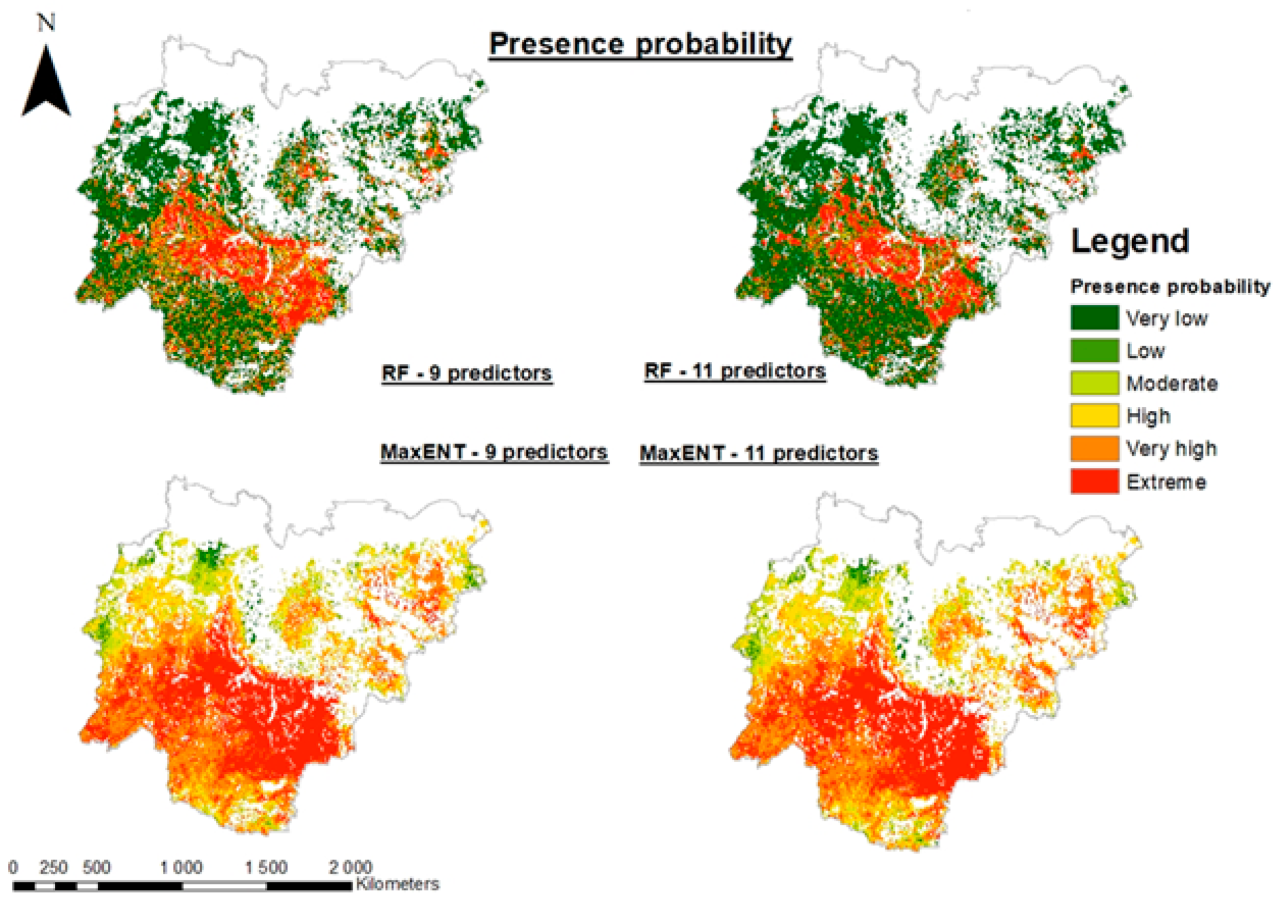
Source: mdpi-res.com
Predicting natural disasters using machine learning isn’t just about building a model; it’s about building a *reliable* model. Accuracy isn’t the whole story; we need to understand how well our model performs across different scenarios and with various types of data. This involves careful evaluation and validation using a range of metrics and techniques. Getting this right is crucial for ensuring the model’s predictions are trustworthy and can be used to inform effective disaster preparedness and response strategies.
Model evaluation in disaster prediction involves assessing the performance of the machine learning model using various metrics and techniques. These metrics provide a quantitative measure of the model’s ability to correctly classify or predict disaster events, while techniques like cross-validation help ensure the model generalizes well to unseen data. Understanding these aspects is vital for building a robust and dependable disaster prediction system.
Evaluation Metrics
Several metrics are commonly used to evaluate the performance of machine learning models for disaster prediction. These metrics offer different perspectives on the model’s strengths and weaknesses, providing a comprehensive evaluation. For instance, simply focusing on overall accuracy can be misleading if the dataset is imbalanced (far more non-disaster events than disaster events).
- Accuracy: The ratio of correctly predicted instances (both true positives and true negatives) to the total number of instances. While seemingly straightforward, accuracy can be deceptive with imbalanced datasets.
- Precision: Out of all the instances predicted as a disaster, what proportion were actually disasters? High precision means fewer false positives (incorrectly predicting a disaster).
- Recall (Sensitivity): Out of all the actual disaster instances, what proportion did the model correctly identify? High recall means fewer false negatives (missing actual disasters).
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure considering both false positives and false negatives. It’s particularly useful when dealing with imbalanced datasets.
For example, in predicting floods, a high recall is crucial to minimize missed warnings, even if it means some false alarms (lower precision). Conversely, in predicting earthquakes, where immediate action might involve costly evacuations, high precision is paramount to avoid unnecessary disruptions.
Cross-Validation Techniques
To ensure the model generalizes well to unseen data – data it hasn’t been trained on – cross-validation is essential. This technique involves splitting the dataset into multiple subsets, training the model on some subsets, and testing it on the remaining subset(s). This process is repeated multiple times, using different subsets for training and testing each time. The average performance across these iterations provides a more robust estimate of the model’s performance.
Common cross-validation methods include k-fold cross-validation (splitting the data into k folds) and leave-one-out cross-validation (using all but one instance for training and the remaining instance for testing). The choice of method depends on the size of the dataset and computational resources. For example, a 10-fold cross-validation might be suitable for a large dataset, providing a good balance between computational cost and accuracy estimation.
Handling Imbalanced Datasets
Disaster datasets are often imbalanced, with far fewer instances of disasters than non-disasters. This imbalance can bias the model towards predicting the majority class (non-disaster), even if the model performs poorly on the minority class (disaster). Several techniques can mitigate this issue:
- Resampling: Techniques like oversampling the minority class (creating copies of existing disaster instances) or undersampling the majority class (removing some non-disaster instances) can balance the dataset. However, oversampling can lead to overfitting, while undersampling might discard valuable information.
- Cost-Sensitive Learning: Assigning different costs to misclassifications (e.g., penalizing false negatives more heavily than false positives) can help the model focus on correctly identifying the minority class. This adjusts the model’s learning process to prioritize the more critical class.
- Ensemble Methods: Combining multiple models trained on different subsets or using different algorithms can improve overall performance and robustness, particularly with imbalanced data. This leverages the strengths of various models to create a more comprehensive prediction.
For instance, in predicting wildfires, oversampling might be used to increase the number of wildfire instances in the training data, leading to better identification of these events.
Best Practices for Reliability and Generalizability
Building reliable and generalizable machine learning models for disaster prediction requires careful attention to several best practices. These practices help ensure the model performs consistently across different datasets and conditions.
- Feature Engineering: Selecting and transforming relevant features (variables) is crucial. Incorporating geographical data, weather patterns, and historical disaster records can significantly improve predictive accuracy.
- Hyperparameter Tuning: Optimizing the model’s parameters using techniques like grid search or random search is essential to find the best configuration for the specific dataset and problem.
- Regularization: Methods like L1 or L2 regularization can prevent overfitting, improving the model’s ability to generalize to unseen data. This helps to avoid overly complex models that perform well on training data but poorly on new data.
- Robustness Testing: Evaluating the model’s performance under various conditions, including noisy data and different input distributions, is crucial to assess its robustness and reliability.
For example, incorporating real-time satellite imagery and weather data into a flood prediction model enhances its accuracy and timeliness, making it more reliable for emergency response.
Applications and Case Studies
Machine learning’s potential in predicting natural disasters isn’t just theoretical; it’s already making a tangible difference in disaster preparedness and response worldwide. Several successful applications demonstrate the power of these predictive models to save lives and mitigate property damage. These case studies highlight the diverse range of algorithms employed and the significant impact achieved through improved prediction accuracy.
The integration of machine learning into disaster prediction systems has shifted from a futuristic concept to a vital tool in modern disaster management. Improved prediction accuracy translates directly into more effective resource allocation, earlier evacuations, and ultimately, a reduction in casualties and economic losses. Let’s explore some compelling examples.
Successful Applications of Machine Learning in Disaster Prediction
The following table showcases several successful applications of machine learning in predicting different types of natural disasters. The results demonstrate the diverse applicability and effectiveness of these techniques.
| Disaster Type | Algorithm Used | Results Achieved | Impact |
|---|---|---|---|
| Hurricane Prediction (e.g., Atlantic hurricanes) | Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) | Improved prediction accuracy of hurricane intensity and track up to 72 hours in advance; better forecasting of rainfall amounts. | Enhanced evacuation planning, improved resource allocation for shelters and emergency services, reduced property damage. |
| Flood Prediction (e.g., Riverine floods) | Support Vector Machines (SVMs), Random Forests | More accurate prediction of flood extent and timing, allowing for timely warnings and preventative measures. | Reduced flood-related fatalities, minimized damage to infrastructure and agriculture, facilitated efficient water resource management. |
| Earthquake Early Warning Systems | Neural Networks, Bayesian Networks | Faster detection and estimation of earthquake magnitude and location, providing crucial seconds to minutes of warning before strong shaking arrives. | Reduced loss of life and infrastructure damage by enabling immediate actions such as halting trains, shutting down gas lines, and initiating automated emergency response systems. |
Impact of Improved Prediction Accuracy: A Hypothetical Scenario
Consider a hypothetical scenario involving a major hurricane predicted to hit a coastal city. Without machine learning, traditional forecasting methods might provide a 72-hour warning with a large margin of error in the predicted landfall location and intensity. This uncertainty could lead to delayed evacuations, insufficient resource allocation (e.g., shelters, emergency personnel), and a less coordinated response.
Now, imagine the same scenario but with a machine learning model providing a 96-hour warning with significantly improved accuracy in the predicted landfall and intensity. This increased lead time and precision allows for a more organized evacuation, ensuring more people can safely leave the danger zone. Emergency services can be strategically deployed to high-risk areas, and resources like food, water, and medical supplies can be pre-positioned effectively. The result? A drastically reduced number of casualties and minimized property damage, showcasing the life-saving potential of enhanced prediction accuracy. The economic benefits alone, in terms of reduced property damage and disruption to businesses, would be substantial. This highlights the clear advantage of machine learning in minimizing loss of life and property in disaster situations.
Challenges and Future Directions
Predicting natural disasters using machine learning offers immense potential, but the journey isn’t without its hurdles. Successfully integrating this technology requires addressing significant challenges and exploring promising avenues for future development. Overcoming these obstacles will unlock the full potential of machine learning in mitigating the devastating impacts of natural disasters.
Data scarcity, computational constraints, and the inherent “black box” nature of some models are key challenges. Moreover, effectively translating model outputs into actionable insights for disaster preparedness and response demands careful consideration of human expertise and system accessibility.
Data Scarcity and Quality
The effectiveness of any machine learning model hinges on the quality and quantity of its training data. For many types of natural disasters, particularly those occurring in less developed regions, comprehensive and reliable historical data is limited. Incomplete datasets, inconsistent data formats, and a lack of ground truth information (accurate records of the actual disaster’s impact) hinder model development and accuracy. For example, accurate flood risk assessments require detailed topographical data, rainfall records, and historical flood extent maps, which may be unavailable or unreliable in many areas. This data scarcity directly impacts the model’s ability to learn meaningful patterns and accurately predict future events. Furthermore, biases present in the available data can lead to skewed predictions, disproportionately affecting vulnerable communities.
Computational Limitations and Model Interpretability, The Role of Machine Learning in Predicting Natural Disasters
Sophisticated machine learning models, while potentially highly accurate, often demand significant computational resources. Training these models can be time-consuming and expensive, particularly when dealing with large datasets and complex algorithms. This can be a major barrier for organizations with limited computational capacity. Additionally, many advanced models, such as deep neural networks, are often described as “black boxes,” meaning their decision-making processes are opaque and difficult to understand. This lack of interpretability makes it challenging to build trust in the model’s predictions and to identify potential biases or errors. For instance, a model predicting earthquake likelihood might produce a high probability, but without understanding *why* it reached that conclusion, it’s difficult to assess its reliability and act upon the prediction confidently.
Integration of New Data Sources and Advanced Algorithms
Future research should focus on integrating diverse data sources to improve model accuracy and robustness. This includes incorporating satellite imagery (providing real-time information on land deformation, flood extent, and wildfire spread), sensor network data (capturing micro-climatic conditions and early warning signals), and social media data (reflecting real-time community experiences and observations). Furthermore, exploring advanced algorithms, such as ensemble methods (combining predictions from multiple models) and explainable AI (XAI) techniques (making model decisions more transparent), holds the key to creating more reliable and trustworthy prediction systems. For example, integrating satellite-based rainfall estimates with ground-based weather station data can provide a more complete and accurate picture of precipitation patterns, improving flood prediction models.
The Role of Human Expertise
Machine learning models should not replace human expertise but rather augment it. Experienced disaster management professionals possess invaluable knowledge of local conditions, vulnerabilities, and response protocols. Effective disaster prediction systems must integrate human judgment and interpretation alongside machine learning outputs. This collaborative approach allows for a more nuanced understanding of the risks and ensures that model predictions are contextualized and effectively translated into action. For example, a machine learning model might predict a high likelihood of a landslide, but a geologist’s assessment of the terrain and soil stability is crucial in determining the precise level of risk and appropriate response strategies.
Improving Accessibility and Usability
To maximize the impact of machine learning-based disaster prediction, systems must be accessible and user-friendly. This requires developing intuitive interfaces that effectively communicate complex information to a diverse range of users, including emergency responders, policymakers, and the general public. Moreover, systems should be designed to function reliably even in situations with limited connectivity or power, ensuring their effectiveness in disaster-prone regions. For instance, a mobile application providing real-time flood warnings in a simple, easily understandable format can empower communities to take proactive measures to protect themselves.
Final Review
Source: mdpi-res.com
In conclusion, the integration of machine learning into natural disaster prediction is not just an advancement; it’s a necessity. While challenges remain, the potential for saving lives and minimizing economic losses is undeniable. As technology evolves and data availability improves, we can expect even more sophisticated and accurate prediction models, ushering in an era of proactive disaster management. The future of disaster preparedness hinges on harnessing the power of machine learning – a future where predictive capabilities transform reactive responses into proactive safeguards.