
The Role of Machine Learning in Predictive Maintenance: Forget crystal balls; the future of maintenance is here. Predictive maintenance, powered by machine learning, is revolutionizing how industries anticipate and prevent equipment failures. From manufacturing plants humming with efficiency to airlines soaring with safety, the impact is undeniable. We’re diving deep into how this game-changing technology is transforming the landscape, exploring its techniques, challenges, and the bright future it promises.
This isn’t just about fixing things *after* they break; it’s about preventing breakdowns before they even happen. Imagine a world where unexpected downtime is a thing of the past, where maintenance is proactive and optimized, and where resources are used more efficiently. That’s the power of predictive maintenance fueled by machine learning.
Introduction to Predictive Maintenance and Machine Learning
Predictive maintenance, a revolutionary approach to asset management, shifts the focus from reactive repairs to proactive interventions. Instead of waiting for equipment to fail, predictive maintenance leverages data analysis to anticipate potential issues and schedule maintenance accordingly, maximizing uptime and minimizing costly breakdowns. This proactive strategy is significantly enhanced by the power of machine learning, opening doors to more accurate predictions and optimized maintenance schedules.
The core principle of predictive maintenance lies in analyzing data from various sources – sensor readings, historical maintenance logs, operational parameters – to identify patterns and anomalies that indicate impending equipment failure. By employing statistical models and machine learning algorithms, predictive maintenance systems can forecast the likelihood of failure with remarkable accuracy, allowing for timely intervention before catastrophic events occur.
Benefits of Machine Learning in Predictive Maintenance
Integrating machine learning into predictive maintenance strategies offers several compelling advantages. Machine learning algorithms, unlike traditional methods, can process vast amounts of complex data, uncovering subtle relationships and patterns that might be missed by human analysts. This leads to more accurate predictions of equipment failure, optimized maintenance schedules, and reduced downtime. Furthermore, machine learning models can adapt and improve over time as they are exposed to new data, leading to increasingly precise predictions. This continuous learning capability is crucial in dynamic operational environments where equipment behavior can change over time. The result is a more efficient and cost-effective maintenance strategy.
Examples of Predictive Maintenance in Various Industries
The impact of predictive maintenance powered by machine learning is felt across numerous industries. In manufacturing, for instance, sensors on production equipment monitor vibration, temperature, and pressure. Machine learning algorithms analyze this data to predict potential malfunctions in motors, bearings, or other critical components, allowing for preventative maintenance before production lines are disrupted. Similarly, in the aviation industry, airlines use machine learning to analyze flight data, engine performance, and sensor readings to predict potential aircraft component failures, ensuring flight safety and reducing costly maintenance delays. The energy sector also benefits greatly; predictive maintenance helps optimize the performance of wind turbines by anticipating potential failures in components like gearboxes and blades, maximizing energy generation and reducing repair costs. These are just a few examples showcasing the transformative power of this technology. The applications are vast and continue to expand as more industries recognize the significant value proposition.
Machine Learning Techniques in Predictive Maintenance
Predictive maintenance, powered by machine learning, is revolutionizing how industries manage their assets. By analyzing sensor data and historical records, these systems can anticipate equipment failures, optimizing maintenance schedules and minimizing downtime. This allows businesses to move from reactive, costly repairs to proactive, cost-effective strategies. Understanding the various machine learning techniques involved is crucial to harnessing the full potential of this technology.
Different machine learning algorithms are suited to different aspects of predictive maintenance. The choice depends heavily on the nature of the data and the specific prediction task. For instance, regression models are ideal for predicting continuous values, such as the remaining useful life (RUL) of a component. Classification models excel at predicting categorical outcomes, like whether a machine will fail within a specific timeframe. Time series analysis is particularly valuable when dealing with sequential data, common in sensor readings from machinery.
Supervised, Unsupervised, and Reinforcement Learning in Predictive Maintenance
The three main categories of machine learning—supervised, unsupervised, and reinforcement learning—each offer unique advantages in the context of predictive maintenance.
Supervised learning methods are the most commonly used. These algorithms learn from labeled data, where each data point is associated with a known outcome (e.g., sensor readings paired with subsequent failure events). This allows the model to learn the relationship between input features and the target variable (e.g., failure). Common examples include regression (linear regression, support vector regression) and classification (support vector machines, random forests, logistic regression) algorithms. These techniques are highly effective in predicting when a specific component might fail.
Unsupervised learning techniques, on the other hand, work with unlabeled data. They aim to discover patterns and structures within the data without explicit guidance. Clustering algorithms, such as k-means, can be used to group similar equipment based on their operating characteristics, potentially identifying machines at higher risk of failure. Anomaly detection algorithms, such as one-class SVM, can identify unusual patterns in sensor data that may indicate impending problems. These methods are useful for identifying potential problems even when historical failure data is scarce.
Reinforcement learning offers a more dynamic approach. It involves training an agent to interact with an environment and learn optimal actions through trial and error. In predictive maintenance, this could involve an agent learning to optimize maintenance schedules based on real-time sensor data and the cost of different maintenance actions. This approach is still relatively new in this field but holds significant promise for optimizing maintenance strategies in complex systems.
Predicting Equipment Failure Using a Specific Algorithm: A Hypothetical Scenario
Let’s consider a scenario involving a wind turbine. We’ll use a Support Vector Regression (SVR) model to predict the remaining useful life (RUL) of a wind turbine’s gearbox. The model would be trained on historical data consisting of various sensor readings (vibration levels, temperature, rotational speed) and the corresponding time until gearbox failure. The input features would be the sensor readings at a given time point, and the target variable would be the RUL (number of operating hours until failure).
The SVR model would learn a function that maps the sensor readings to the RUL. This function would then be used to predict the RUL for new sensor readings from the gearbox. For instance, if the model predicts a RUL of 500 hours, maintenance could be scheduled proactively to avoid a costly and disruptive failure. This proactive approach would minimize downtime and optimize maintenance costs compared to a reactive approach based on scheduled maintenance or failure-driven repairs. Regular monitoring and retraining of the model with new data would further improve its accuracy and adaptability over time, as operating conditions and equipment performance may change.
Data Acquisition and Preprocessing for Predictive Maintenance
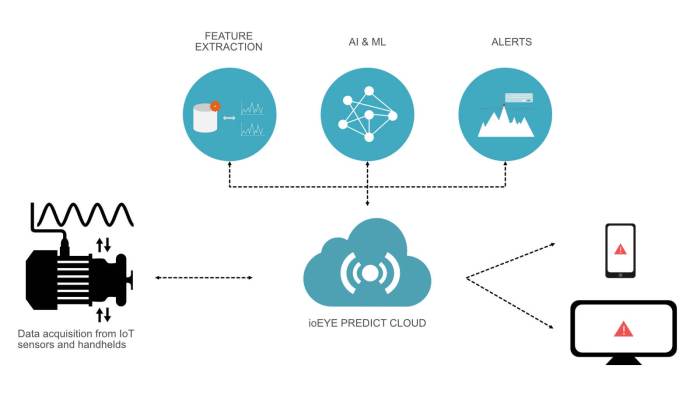
Source: nextengineering.in
Predictive maintenance relies heavily on the quality and quantity of data. Garbage in, garbage out, as they say – so getting the right data and cleaning it up is crucial for accurate predictions and effective maintenance strategies. This section delves into the sources of this vital data and the essential preprocessing steps to transform raw information into valuable insights.
The effectiveness of predictive maintenance hinges on the ability to gather and process relevant data effectively. This involves identifying key data sources, understanding the inherent challenges in data quality, and employing appropriate preprocessing techniques to prepare the data for machine learning models.
Predictive maintenance, powered by machine learning, optimizes downtime by anticipating equipment failures. This efficiency extends beyond individual machines; understanding the entire supply chain’s health is crucial, and that’s where transparency comes in – check out this article on How Blockchain Technology is Enhancing Supply Chain Transparency to see how. Ultimately, a clearer supply chain view allows for more accurate predictive models, leading to even better machine maintenance strategies.
Key Data Sources for Predictive Maintenance
Data for predictive maintenance comes from various sources, each offering unique insights into the health and performance of equipment. These sources, when combined, paint a comprehensive picture enabling accurate predictions.
Three primary data sources are particularly important: sensor data, operational logs, and historical maintenance records. Let’s examine each in detail.
- Sensor Data: Sensors embedded within equipment continuously monitor various parameters like temperature, vibration, pressure, and current. This real-time data provides crucial indicators of potential failures.
- Operational Logs: These logs record operational parameters such as run time, load levels, and environmental conditions. This contextual information helps interpret sensor data and identify patterns associated with equipment degradation.
- Historical Maintenance Records: These records detail past maintenance activities, including repair types, replacement parts, and downtime. This historical information provides valuable context and helps validate model predictions.
Challenges in Data Quality and Mitigation Strategies
Raw data is rarely perfect. Several challenges can impact data quality, potentially leading to inaccurate predictions. Addressing these challenges is crucial for successful predictive maintenance.
Common issues include missing values, outliers, and noise. Let’s explore each and discuss effective solutions.
- Missing Values: Sensor malfunctions or data transmission errors can lead to missing data points. Strategies for handling missing values include imputation (filling in missing values using statistical methods like mean, median, or more sophisticated techniques like k-Nearest Neighbors), or removal of data points with extensive missing values.
- Outliers: Outliers are data points significantly deviating from the norm. They can skew model training and lead to inaccurate predictions. Methods for handling outliers include removal (if deemed erroneous), transformation (e.g., using logarithmic transformations), or robust statistical methods less sensitive to outliers.
- Noise: Noise represents random errors or fluctuations in the data. Techniques like smoothing (applying moving averages or other filtering methods) can reduce noise and improve data quality.
Data Preprocessing Steps for Predictive Maintenance
Data preprocessing is a crucial step in preparing data for machine learning models. A structured approach ensures the data is clean, consistent, and ready for analysis. The following table Artikels a step-by-step guide.
| Step | Technique | Description | Example |
|---|---|---|---|
| 1. Data Cleaning | Handling Missing Values | Imputation (mean, median, k-NN) or removal of rows/columns with excessive missing data. | Replacing missing temperature readings with the average temperature from the previous hour. |
| 2. Data Transformation | Normalization/Standardization | Scaling features to a similar range (0-1 or mean=0, std=1) to prevent features with larger values from dominating the model. | Scaling vibration readings to a range between 0 and 1 using Min-Max scaling. |
| 3. Feature Engineering | Creating new features | Generating features that capture relevant patterns or relationships from existing features (e.g., calculating ratios, differences, or time-based aggregates). | Calculating the ratio of current to voltage to detect anomalies. |
| 4. Outlier Detection and Handling | IQR method, Z-score | Identifying and removing or transforming data points that significantly deviate from the norm. | Removing temperature readings that are more than 3 standard deviations from the mean. |
Model Development and Evaluation
Building robust predictive maintenance models isn’t just about throwing data at an algorithm; it’s a meticulous process requiring careful consideration at each stage. From selecting the right algorithm to interpreting the results, a strategic approach is key to unlocking the true potential of predictive maintenance. This section delves into the critical aspects of model development and evaluation, providing practical insights for achieving optimal performance.
Effective model development hinges on a balance between rigorous training and robust validation. The goal isn’t just to achieve high accuracy on training data, but to build a model that generalizes well to unseen, real-world data – ensuring accurate predictions for your equipment’s future health. This involves careful selection of features, appropriate algorithm choice, and a thorough validation strategy to avoid overfitting and ensure reliable predictions.
Model Training and Validation Best Practices
Training a machine learning model for predictive maintenance involves feeding it a dataset of sensor readings, historical maintenance records, and other relevant information. The model learns patterns and relationships within this data to predict future equipment failures. Validation, however, is crucial to assess the model’s performance on unseen data, ensuring it can accurately predict failures in real-world scenarios. This involves splitting the dataset into training, validation, and testing sets. The training set is used to train the model, the validation set to tune hyperparameters and prevent overfitting, and the testing set to provide a final unbiased evaluation of the model’s performance. Cross-validation techniques, like k-fold cross-validation, further enhance the robustness of the evaluation by training and testing the model on multiple subsets of the data. For example, a 5-fold cross-validation would split the data into five folds, training the model on four folds and testing on the remaining fold, repeating this process five times with a different fold used for testing each time. The average performance across all five folds provides a more reliable estimate of the model’s generalization ability.
Model Evaluation Metrics
Several metrics are used to evaluate the performance of predictive maintenance models. The choice of metric depends on the specific application and the relative costs of false positives (predicting a failure when none will occur) and false negatives (failing to predict an impending failure).
- Precision: Measures the proportion of correctly predicted positive cases (failures) out of all cases predicted as positive. A high precision indicates fewer false positives. For instance, if a model predicts 10 failures and 8 are actual failures, the precision is 80%.
- Recall (Sensitivity): Measures the proportion of correctly predicted positive cases (failures) out of all actual positive cases. High recall indicates fewer false negatives. Using the same example, if there were 10 actual failures, the recall is 80%.
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure of both. It’s particularly useful when dealing with imbalanced datasets (more instances of one class than another).
- AUC (Area Under the ROC Curve): Represents the model’s ability to distinguish between positive and negative cases across different thresholds. A higher AUC indicates better discrimination ability. The ROC curve plots the true positive rate (recall) against the false positive rate at various classification thresholds.
Consider a scenario where a manufacturing plant uses a predictive maintenance model to predict equipment failures. A high recall is crucial to minimize unexpected downtime, even if it means some false positives (scheduled maintenance for equipment that wouldn’t have failed). Conversely, in a context with high maintenance costs, a high precision might be prioritized to avoid unnecessary interventions.
Interpreting Model Results and Refinement, The Role of Machine Learning in Predictive Maintenance
Interpreting model results involves analyzing the chosen evaluation metrics and understanding the model’s strengths and weaknesses. Visualizations, such as confusion matrices and ROC curves, can be invaluable in this process. Identifying areas for improvement requires a systematic approach.
- Feature Engineering: Explore additional relevant features or transform existing ones to improve model performance. For example, creating new features like rolling averages or ratios of sensor readings can capture subtle patterns missed by the original features.
- Algorithm Selection: Experiment with different machine learning algorithms to find one better suited to the data and problem. Consider algorithms like Support Vector Machines (SVMs), Random Forests, or Gradient Boosting Machines (GBMs), each having strengths and weaknesses.
- Hyperparameter Tuning: Optimize the model’s hyperparameters using techniques like grid search or randomized search to find the optimal settings for the chosen algorithm.
- Data Augmentation: If the dataset is small, consider techniques to increase its size by generating synthetic data points based on the existing data.
- Addressing Class Imbalance: If the dataset has a significant class imbalance (e.g., many more instances of ‘no failure’ than ‘failure’), techniques like oversampling the minority class, undersampling the majority class, or using cost-sensitive learning can improve model performance.
Deployment and Monitoring of Predictive Maintenance Models
Predictive maintenance models, once trained and validated, need to be seamlessly integrated into the operational workflow to deliver real-world value. This involves careful consideration of deployment strategies and ongoing monitoring to ensure continued accuracy and effectiveness. Ignoring these crucial steps can render even the most sophisticated model useless.
Deployment strategies need to be tailored to the specific context of the application and the available infrastructure. A simple model might be integrated directly into an existing system, while a more complex one might require a dedicated server or cloud-based solution. The choice also depends on factors like data volume, model complexity, and real-time requirements.
Deployment Strategies for Predictive Maintenance Models
Several deployment methods exist for integrating machine learning models into a predictive maintenance system. The optimal strategy depends on factors such as the model’s complexity, real-time requirements, and the existing IT infrastructure.
- On-Premise Deployment: The model runs on servers within the organization’s own data center. This offers greater control and security but requires dedicated IT resources for maintenance and updates. This approach is suitable for organizations with substantial IT infrastructure and a need for high security and low latency.
- Cloud-Based Deployment: The model is hosted on a cloud platform (e.g., AWS, Azure, GCP). This offers scalability and flexibility, allowing the system to handle fluctuating workloads. Cloud deployment is particularly advantageous for organizations lacking significant in-house IT infrastructure or those needing rapid scalability.
- Edge Deployment: The model runs on devices close to the data source (e.g., sensors on machinery). This minimizes latency and reduces reliance on network connectivity, ideal for remote or geographically dispersed assets. Edge deployment is particularly well-suited for applications requiring immediate action based on predictions, such as real-time alerts for imminent equipment failure.
- Hybrid Deployment: A combination of on-premise and cloud-based deployment, leveraging the strengths of both approaches. This allows organizations to maintain control over sensitive data while benefiting from the scalability and flexibility of the cloud.
Model Monitoring and Retraining
Model monitoring is paramount to ensure the continued accuracy and reliability of predictive maintenance models. Over time, the relationship between input data and predicted outcomes can drift due to changes in equipment, operating conditions, or even data quality. This necessitates regular monitoring and retraining to maintain the model’s predictive power.
Regular monitoring involves tracking key performance indicators (KPIs) such as precision, recall, F1-score, and AUC. Anomalies in these metrics can signal a decline in model performance, prompting a retraining process. Retraining involves using updated data to refine the model and restore its accuracy. This might involve incorporating new data, adjusting model parameters, or even selecting a different algorithm altogether. For instance, a manufacturing plant might retrain its predictive maintenance model annually, incorporating data from the past year to account for seasonal variations in production or equipment wear.
Hypothetical System Architecture
Imagine a system for predicting bearing failures in wind turbines. The system would comprise several key components. First, sensors on each turbine collect vibration data, temperature, and rotational speed. This data is transmitted wirelessly to a central data hub (potentially cloud-based). A data preprocessing module cleanses and prepares the data for model input. The predictive model (e.g., a recurrent neural network) processes this data to generate predictions of bearing failure probability. These predictions are then fed into a monitoring dashboard, alerting maintenance personnel to potential issues. A feedback loop allows engineers to manually correct predictions or add new data points to improve the model’s accuracy. The entire system is designed for scalability, allowing for the monitoring of hundreds or even thousands of turbines simultaneously. The system also incorporates automated alerts and reporting features, which are triggered based on pre-defined thresholds in the model’s predictions. This allows for proactive maintenance scheduling, minimizing downtime and optimizing maintenance resource allocation.
Case Studies and Real-World Applications
Predictive maintenance powered by machine learning isn’t just a theoretical concept; it’s transforming industries worldwide, delivering tangible benefits and reshaping operational strategies. Real-world deployments showcase its power to optimize resource allocation, minimize downtime, and significantly reduce maintenance costs. Let’s delve into some compelling examples.
Predictive Maintenance in the Wind Energy Sector
The wind energy industry faces unique challenges due to the remote location and harsh environmental conditions of wind turbines. Traditional reactive maintenance strategies are costly and inefficient. Machine learning algorithms, trained on sensor data from wind turbines (vibration, temperature, power output, etc.), can predict potential failures, such as gear box issues or blade damage, with remarkable accuracy. Companies like Vestas and Siemens Gamesa have implemented these systems, resulting in reduced downtime, optimized maintenance schedules, and extended turbine lifespan. For instance, one study showed a 20% reduction in unplanned downtime after implementing a machine learning-based predictive maintenance system. Overcoming challenges like data scarcity (especially in older turbines with limited sensor data) often involves combining machine learning with domain expertise and data augmentation techniques.
Machine Learning in Manufacturing: A Case Study of Predictive Maintenance for CNC Machines
Computer Numerical Control (CNC) machines are the backbone of many manufacturing processes. Unexpected failures can lead to significant production delays and financial losses. Implementing machine learning for predictive maintenance involves collecting data from various sensors on the CNC machines (vibration, temperature, motor current, etc.). This data is then used to train machine learning models (such as Random Forests or Support Vector Machines) to predict potential failures, allowing for proactive maintenance before catastrophic breakdowns occur. A leading automotive manufacturer reported a 15% reduction in maintenance costs and a 10% increase in production efficiency after implementing a machine learning-based predictive maintenance system for their CNC machines. A key challenge here is dealing with the high dimensionality and noisy nature of sensor data, often requiring careful feature engineering and data cleaning.
Comparison with Traditional Methods
Traditional reactive maintenance relies on scheduled maintenance or repairs only after a failure occurs. This approach is inefficient, leading to unexpected downtime, higher repair costs, and increased safety risks. Preventive maintenance, while an improvement, often involves overly frequent inspections and replacements, leading to unnecessary expenses. Machine learning-based predictive maintenance offers a superior approach by focusing maintenance efforts only when and where they are truly needed. The result is a significant reduction in both maintenance costs and downtime, while simultaneously improving operational efficiency and safety. The improved accuracy and efficiency offered by machine learning translate to substantial cost savings and a significant competitive advantage for businesses. For example, a comparison study showed that machine learning-based predictive maintenance reduced maintenance costs by 30% compared to traditional methods in a large-scale manufacturing facility.
Future Trends and Challenges
Predictive maintenance, while already revolutionizing industries, stands at the cusp of even more significant advancements. The convergence of emerging technologies and the increasing availability of data promise further improvements in efficiency, accuracy, and cost-effectiveness. However, these advancements also bring forth new challenges, particularly in ethical considerations and data management.
The integration of cutting-edge technologies is poised to reshape the landscape of predictive maintenance. This evolution will not only enhance the capabilities of existing systems but also open doors to entirely new approaches and applications.
Emerging Technologies and Their Impact
The Internet of Things (IoT), edge computing, and advanced AI algorithms are rapidly transforming predictive maintenance. IoT devices embedded within machinery generate vast amounts of real-time data, providing a continuous stream of information about equipment health. Edge computing processes this data closer to its source, reducing latency and bandwidth requirements. Advanced AI, including deep learning and reinforcement learning, enables the development of more sophisticated predictive models capable of handling complex datasets and identifying subtle patterns indicative of impending failures. For example, a wind turbine farm leveraging IoT sensors and edge computing can analyze vibration data in real-time, predicting potential gear failures days in advance, allowing for proactive maintenance and preventing costly downtime. This proactive approach minimizes disruptions and extends the operational lifespan of the turbines.
Ethical Considerations and Potential Biases
The use of machine learning in predictive maintenance raises ethical concerns, primarily regarding potential biases in algorithms and their impact on decision-making. If the training data reflects existing biases, the resulting models may perpetuate and even amplify these biases, leading to unfair or discriminatory outcomes. For instance, a model trained on data primarily from well-maintained equipment in a specific geographic location might inaccurately predict the maintenance needs of equipment operating under different conditions or in different regions. This could lead to inadequate maintenance and potential safety risks. Rigorous testing, diverse datasets, and ongoing monitoring are crucial to mitigate these biases.
Data Security and Privacy Challenges
The increasing reliance on data in predictive maintenance systems necessitates robust security measures to protect sensitive information. Data breaches can compromise operational efficiency, intellectual property, and even physical safety. Furthermore, the collection and use of data must adhere to relevant privacy regulations, ensuring the responsible handling of personal and sensitive information. Implementing strong encryption protocols, access control mechanisms, and regular security audits are essential for mitigating these risks. Consider, for example, a manufacturing plant employing predictive maintenance to monitor its machinery. This data might include details about production processes and potentially sensitive employee information. Protecting this data from unauthorized access is paramount to maintain both operational security and employee privacy.
Closure: The Role Of Machine Learning In Predictive Maintenance
The integration of machine learning into predictive maintenance is no longer a futuristic fantasy; it’s a rapidly evolving reality reshaping industries worldwide. While challenges remain – data quality, ethical considerations, and security – the potential benefits are too significant to ignore. By embracing this technology and addressing its complexities head-on, businesses can unlock unprecedented levels of efficiency, reliability, and cost savings. The journey toward smarter, more predictive maintenance is underway, and the future looks remarkably efficient.